Explainable Machine Learning for Probability of Default Calculations
How the FICO Platform can enable explainable machine learning models for more effective PD calculations

In my last post I looked at using predictive machine learning models (specifically, a boosted ensemble like xGB Boost) to improve on Probability of Default (PD) scoring and thereby reduce RWAs. The results were quite impressive at determining default rate risk – a reduction of up to 20 percent. Default prediction like this would make any balance sheet owner happy – empowering lenders to more accurately predict which borrower presents a credit risk.
To ensure accurate forecasting, we need to not only determine probability of default but also create explainable machine learning models, which is harder than with traditional scorecards. One needs to lay out how the algorithm impacts the credit risk decision, in a way that is accurate, scalable and easy to review. So let’s see how a machine learning algorithm can be managed within our FICO Business Outcome Simulator (BOS), to offer these more accurate prediction methods.
To do this, I used the xAI toolkit in FICO Analytics Workbench, part of the capabilities available on FICO Platform, and that means I can create a Python container with my machine learning model, with all its explainability, and use it elsewhere.
Quick Access to explainability for machine learning models
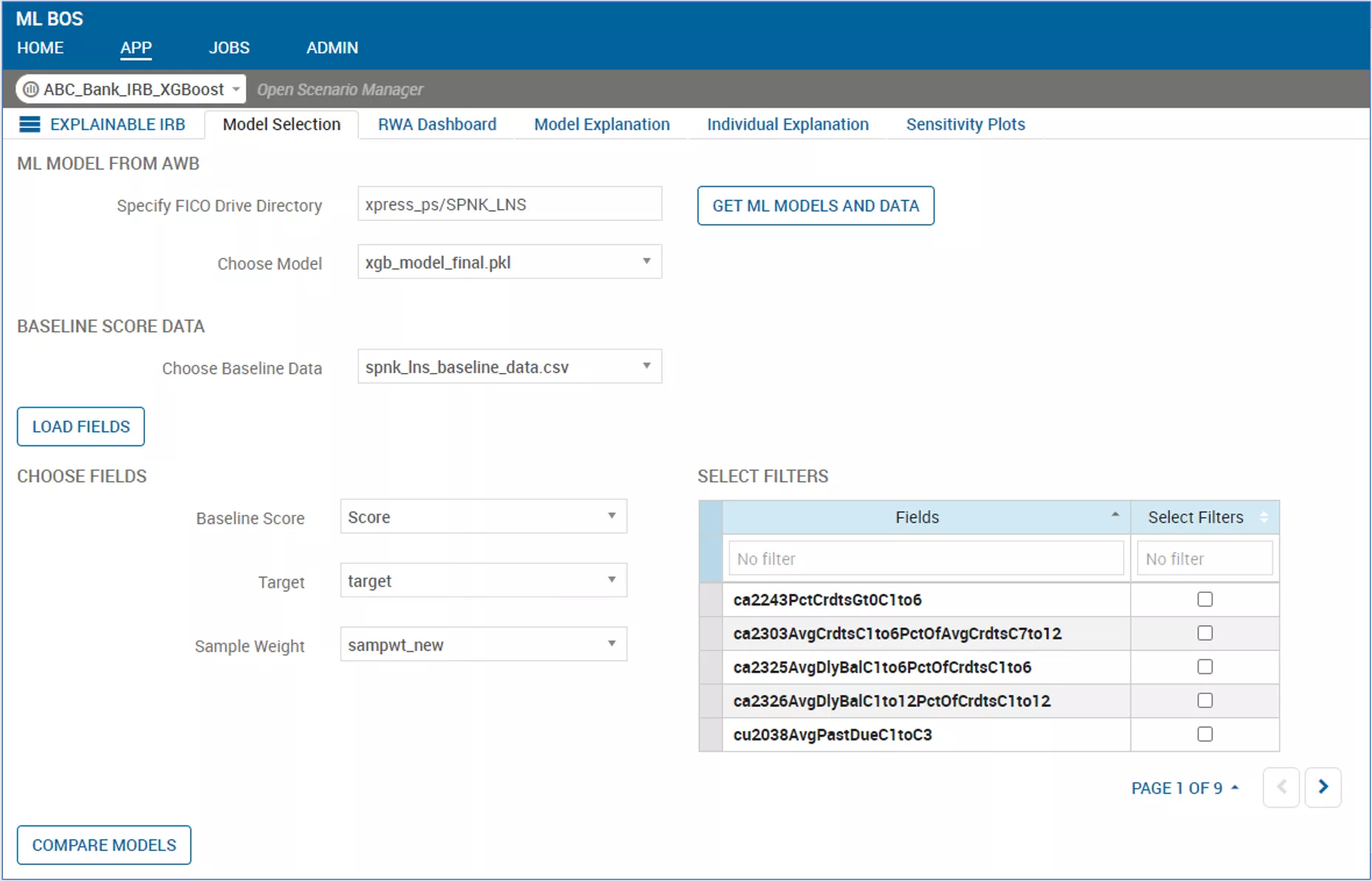
With my colleague Prasanth, we put together a toolkit in FICO Business Outcome Simulator (BOS) to allow capital model managers quick access to explainability of their new machine learning algorithms. From comparing the old to new results quickly (and allowing a deep dive into different segments) to exploring the individual records to see why they received the Probability of Default (PD) they did, the power of Xpress Insight lets us create any dashboard or report we want, and gives us the capability of executing models and explainability natively with greater accuracy and flexibility.
How does it work? We start by bringing in the current Probability of Default (PD) model and then creating a candidate model with data supplied by the client. We use Analytics Workbench to produce the machine learning Probability of Default (PD) model and add it alongside the current model on the BOS shelf. From here we can run a risk-weighted assets (RWA) comparison (as precise as possible, depending on other data supplied by the client) and show the differences in the prediction on a full portfolio basis or filtered down using any of the data fields available.
Now it gets interesting. Although we built the explainable machine learning model inside Analytics Workbench — accessing the unique FICO code libraries that are available on the FICO Platform for interpreting all kinds of tree ensemble models — because these xAI libraries are a core capability on the Platform, and because we can run Python code natively in different places as required, we can show the model interpretability details within BOS.
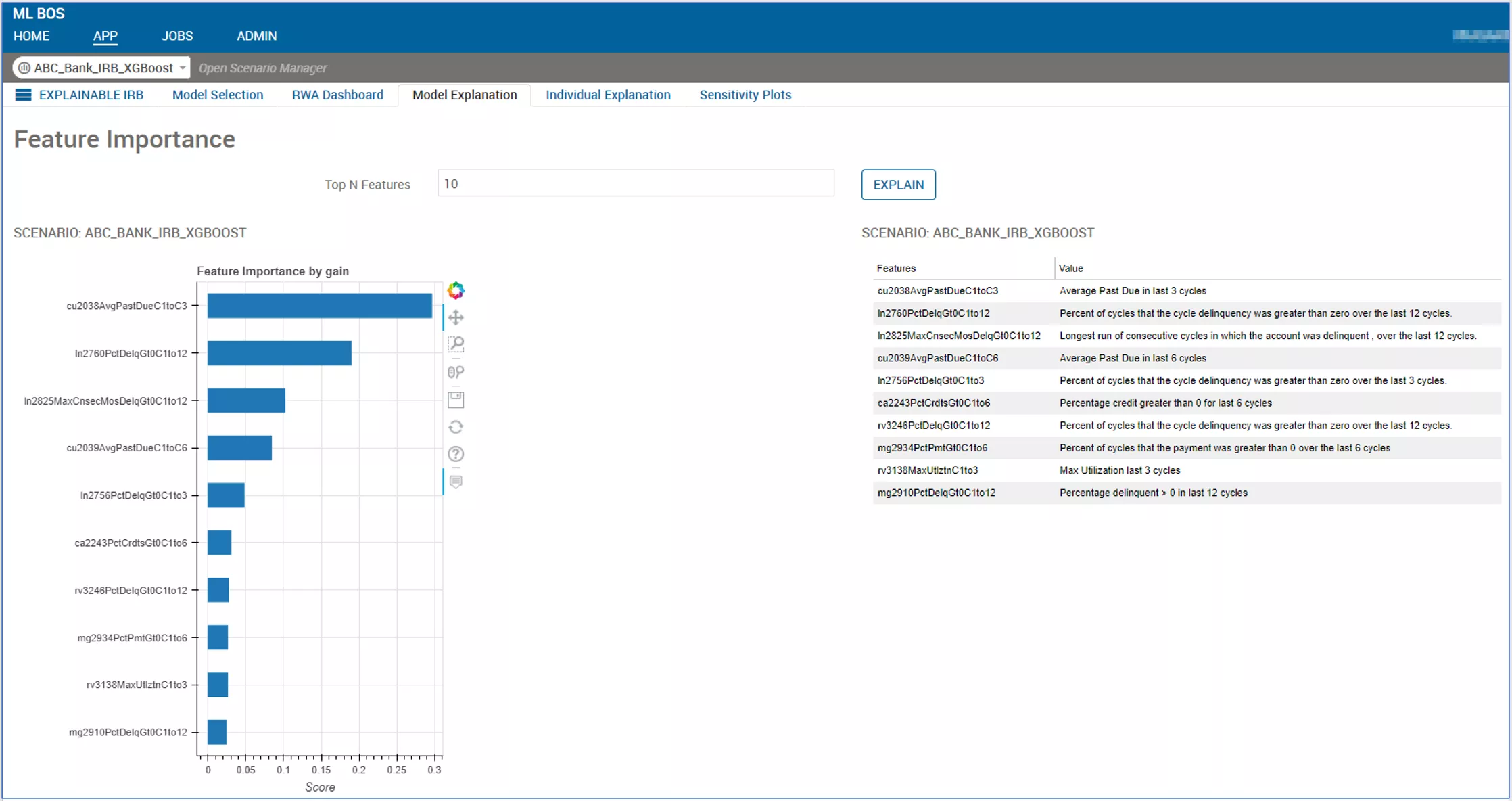
First up are the model-level variable explanations. The Feature Importance statistics are just the tip of the iceberg of what we can show here. Behind the scenes the algorithm is generating Partial Dependency Plots, Group Performance Metrics on a variable-by-variable basis, aggregated feature contribution visualisations (violin plots are popular for this), ICE plots, pairwise feature importance diagrams and more. All these things can be brought out and displayed with BOS.
Method to get the individual default prediction of a borrower
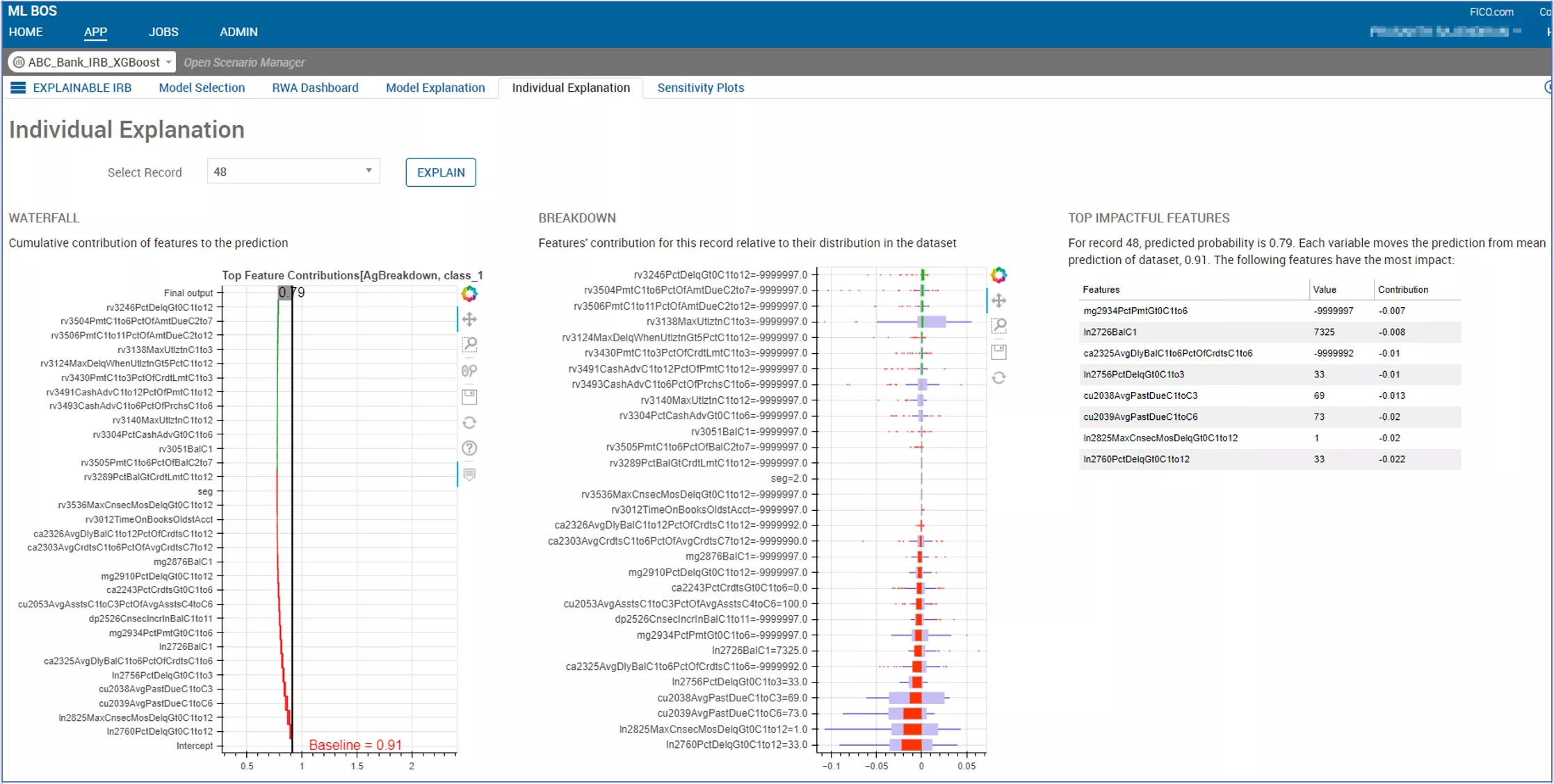
Next, we move to individual instance explanations. Here we can show how the fields for an individual account or borrower contribute to the final score and can display how those contributions compare to the broader model build dataset. Digging deeper, we can provide sensitivity curves giving a unique view for each exposure as to how their Probability of Default (PD) might change if individual variables are altered.
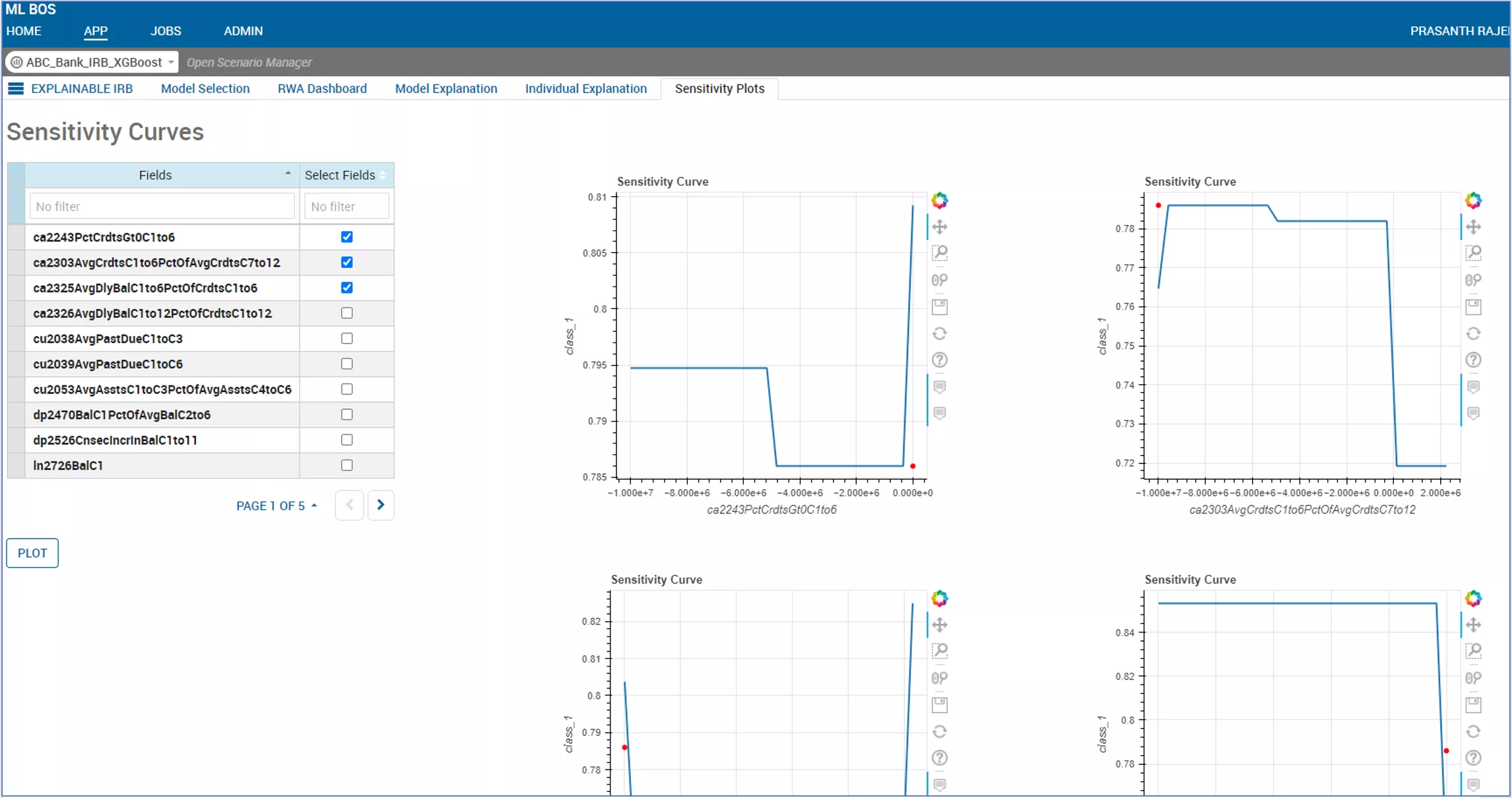
With this method, the combination of macro- and micro-level analysis provides assurance that, subject to regulatory approval, moving to machine learning Probability of Default (PD) models not only delivers RWA improvements, it means that the new machine learning models can be explained at the model and individual instance level, a necessary criterion for both internal and external audiences.
If you’re interested in finding out how FICO xAI and the power of the Decision Management Platform can enhance your life-cycle model execution or provisioning and capital calculations, do let us know. With regulators around the world increasing looking approvingly at the use of machine learning solutions in these areas, FICO can enable banks to be at the forefront of innovation for Pillar 1 and Pillar 2 RWA calculations.
With thanks to Prasanth Rajendiran and the FICO Business Outcome Simulator team
How FICO Can Help You Improve Loss Calculations

Popular Posts

Has the Reporting of Rental Data to the Credit Reporting Agencies (CRAs) Increased?
FICO Score 10T includes rental data, but consumers can only experience the benefit of this to the extent that their rental data is reported to the CRAs
Read more
Average U.S. FICO® Score at 716, Indicating Improvement in Consumer Credit Behaviors Despite Pandemic
The FICO Score is a broad-based, independent standard measure of credit risk
Read more
FICO Statement on FHFA and FHA Updates to Credit Score Modernization
FICO supports FHFA’s announcement that the long-anticipated historical data for FICO® Score 10T will be released to the mortgage market.
Read moreTake the next step
Connect with FICO for answers to all your product and solution questions. Interested in becoming a business partner? Contact us to learn more. We look forward to hearing from you.