Bank Ecosystems: The Role of Data Ingestion
Multiple types of data can be fed into banking systems to make better decisions - but can your system handle it?

In my previous blog post, I talked about how open banking can be leveraged to build a financial ecosystem and what capabilities are required to get the maximum value from it. Now I want to deep dive into each of these capabilities, explain why we need them and show how we can best use them for different customer decisions in the financial ecosystem. I’d like to start with data ingestion, as the medium is the message and data is your medium. Data needs to be fed, shared, enriched, stored and used in the banking ecosystem for several different decisions.
In the example in my previous blog, I had drafted a banking ecosystem which can penetrate into customers’ lifecycle with different products and services. Let’s assume the lender in this example is aiming to grow its new-to-system customer portfolio via launching a new digital lending product: small-ticket unsecured instalment loans. In today’s world, given the various alternative data resources available, the challenge for lenders becomes managing a diverse set of data, especially when making decisions on people who are new to credit.
To launch this new product, the lender will identify the marketing strategy and credit risk criteria applicable to this digitally savvy millennial & iGen customer personas. The key success factor will be to be able to capture the application data in a digitally innovative way and to decision the applications almost instantly with low friction but with an adequate KYC, AML and application fraud control. In order to achieve this, at the time of application, all types of data will need to be accessible in real time. The challenge will be the fact that the data will be retrieved from several different internal and external sources and will be in completely different formats:
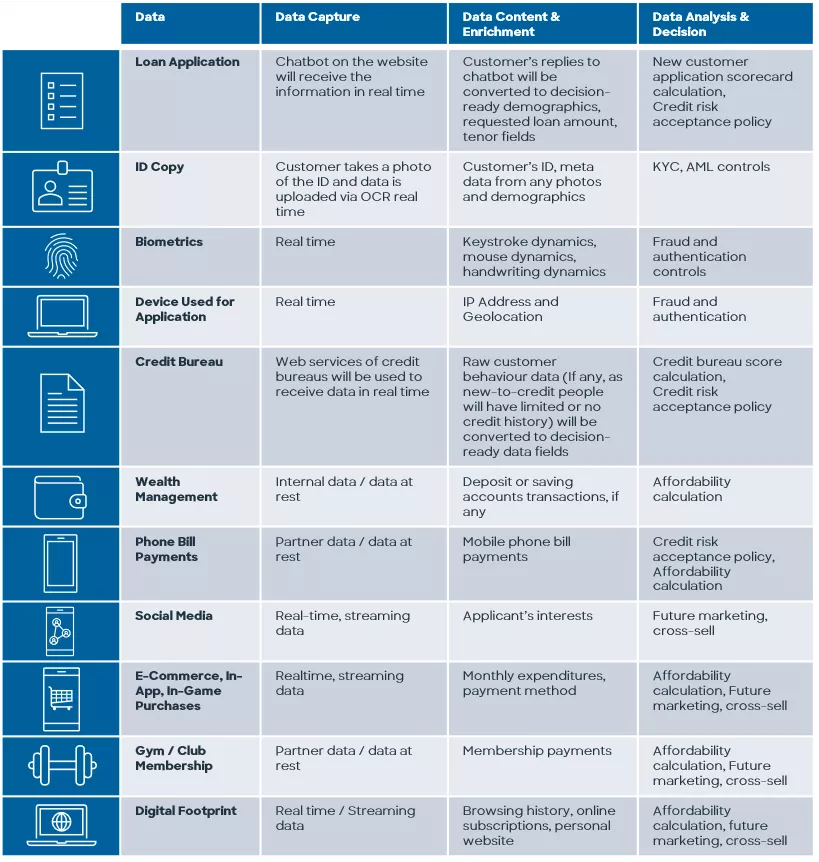
Clearly, the use of some of these data sources — particularly those related to social media and online activity — would not be permitted for credit decisions in some countries. But in every case, there are some countries where this kind of data is being used or explored, often with the customer’s express permission. For more information, see our white paper on “Can Alternative Data Expand Credit Access?”
A strong data ingestion capability is playing an important role at this stage. All this data can be accurately captured, processed and used in real-time for above decisions simultaneously, even can be stored in a single data mart for use in future, if your data ingestion capability is strong. Today most technologies are struggling with bringing such data together from various streams (at rest, in motion, streaming) into one stream. However, for an instant, digital credit decision process, this capability is a must.
So what do I mean by “strong data ingestion capability”? Let’s assume the lender would like to offer a pre-approved instalment loan instantly, when the customer makes a credit card purchase transaction above a certain amount. In order to achieve this, the bank needs to monitor the transactions in the customer’s credit card account in real time. The data ingestion layer must have the capability of constantly monitoring the transaction data and storing the new information immediately as it is generated. Also, for a consumer bank with thousands or even millions of credit card customers, the volume of the streaming data can be quite large. Hence the data ingestion process must be capable of processing large volume of data.
The other challenge would be the required speed of the data ingestion process, as the lender would like to create the loan offers instantly. For the system to recognize whether the transaction is a debit or credit to account, to be able to differentiate a credit card purchase from a payment may also require some pre-processing of the data. Additionally, for a pre-approved credit offer to be generated, the lender will need to combine this internal data with external data, such as updated credit bureau information-. So, the data ingestion layer should be capable of connecting with such external data in real time, cleaning it and transforming it into decision-ready characteristics.
For a personalized customer engagement across customer lifecycle, a lender would be able to easily control what external data to access and how often to access it to control costs. For example, credit bureau data acquired at the time of origination and the calculated decision keys produced from this data can be re-used later for re-scoring processes in portfolio management, or identifying target customers for a cross-sell campaign without having to pay the fee to pull another credit report.
The other capability the lender would benefit from is the elimination of data silos. By aggregating multiple data sources, making them available centrally for the use of different teams and eliminating self-limiting and costly silos, a lender can get the full value from the data.
In my next post, I’ll write about characteristics libraries, how to create attributes or decision key variables and for which credit decisions or analytical models we can use them. In the meantime, you can check out these resources for more information on the data ingestion and use of external data:
https://www.fico.com/en/products/fico-data-orchestrator
https://www.fico.com/en/products/fico-decision-management-platform-streaming

Popular Posts

Has the Reporting of Rental Data to the Credit Reporting Agencies (CRAs) Increased?
FICO Score 10T includes rental data, but consumers can only experience the benefit of this to the extent that their rental data is reported to the CRAs
Read more
FICO Statement on FHFA and FHA Updates to Credit Score Modernization
FICO supports FHFA’s announcement that the long-anticipated historical data for FICO® Score 10T will be released to the mortgage market.
Read more
Average U.S. FICO® Score at 716, Indicating Improvement in Consumer Credit Behaviors Despite Pandemic
The FICO Score is a broad-based, independent standard measure of credit risk
Read moreTake the next step
Connect with FICO for answers to all your product and solution questions. Interested in becoming a business partner? Contact us to learn more. We look forward to hearing from you.