Defining Big Data Characteristics – A Data Scientist’s Life Hack
Unless you are good at generating the right data characteristics, or features, which are relevant to your business decisions, you cannot increase the value of big data

In my previous post I talked about external data and data ingestion capabilities a financial platform must have. Now I’d like to describe the capability of developing big data characteristics, how important this capability is for a financial platform and how banks can use this capability to boost the value received from the data they can access.
Most data scientists and analysts would be aware of the so-called four Vs of big data:
- Velocity – The speed at which the data is generated
- Volume – The size of the data
- Variety – The different types of the data
- Variability – The rate of change in a data set
Now people talk about the seven Vs, including:
- Veracity – The reliability of the data
- Visualization – The ability to see the data to discover patterns
- Value – The business benefit we can gain using that data
I believe the most important factor of all is value!
What is the value of the data for your business decision and how can you maximize it?
One common misconception is that if the 6 other V’s of data are improved, the value of the data will be increased. In fact, there is no such linear relationship. Unless you are good at driving the correct characteristics, or features, from the data, which are relevant to your business decisions, you cannot increase its business value.
What Is a Feature?
Features are data elements that are used as inputs to an analytical model. Choosing what features to use is important for a machine learning model. It is the key because some of the features will actually drive outcomes but some of them will not.
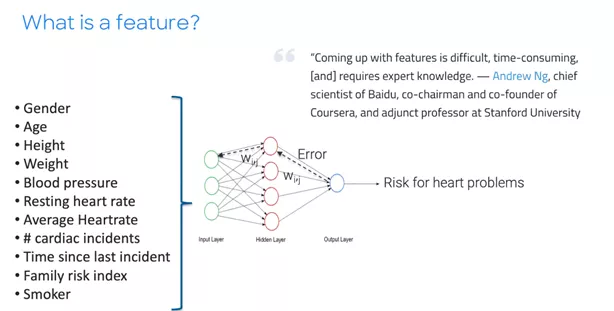
Few organizations are able to generate decision-ready characteristics to take the full advantage of all available data. In order to do that, you should have experienced data scientists in your organization. However, each business decision requires different data characteristics and there are so many different decisions a typical bank takes in their business processes, it’s almost impossible for one data scientist to get to know which characteristics are more predictive than others in every one of these decisions.
From Decisions to Questions to Characteristics
Following up on the same unsecured instalment loan example in my previous posts, below is an example set of decisions a bank takes for managing an unsecured instalment loan through the customer lifecycle and some predictive characteristics which your data scientists need to develop:


There are hundreds more characteristics generated and analysed before a final customer decision is given at banks. Above is only an example to show that there is a wide variety of predictive characteristics a bank needs to generate from the data available at the time of that specific customer decision.
To manage this variety, banks tend to work with different analytics consultants specialized in each one of these decisions, or build separate specialized teams working in silos, typically without having access to the same data mart. These teams also develop different characteristics, either using the machine learning processes or with the help of data analysts’ experience. While these characteristics can be used for different decisions across the organization, each team cannot access the other team’s characteristics to validate and/or understand how valuable these are to their own business decisions.
Centralized Characteristic Generation
That’s why centralization is important to maximizing the effectiveness of the characteristic generation process and making it more cost-effective. We also observe that organizations are starting to simplify their machine learning pipelines and create a more collaborative environment for data analysts working on machine learning. Having a centralized characteristic library would definitely accelerate this effort. By sharing features / attributes / characteristics across an organization, different data scientists and decision modelers can use them for different decisions and there will be no need to compute them many times.
Now whether your external data comes from a credit bureau, social media or a government website, the bank and its competition have access to the same external data. The competitive advantage comes in the speed with which you can understand the predictive value of data characteristics and translate those characteristics into decision-ready keys. There is no time to waste via making champion-challenger tests on the data characteristics. The bank must have an established, easy-to-access characteristic library in order to do that, such as the feature store in the FICO Platform.
Another feature banks should consider in a characteristic library is how much they allow different approaches to analysts when they’re exploring the data. An example is when data scientists need to analyse the data without having a clear definition of what they’re looking for. This often happens in a pre-crisis period, where the portfolio delinquencies are on the rise and portfolio managers try to understand what is causing the issue. In this case, analysts explore the data, looking for some co-related patterns. The characteristic library must then provide different ways for analysts to view and investigate the data, pull in new data, merge, create and use new data characteristics. This makes the analysis powerful when it comes to working on machine learning and helps with operationalizing machine learning into production systems.
In my next post, I’ll write about microservices, which are another tool data scientists use to make strategy generation easier and more effective.
In the meantime, you can explore these links for more information on how to build and use a data characteristics library:
https://www.fico.com/en/latest-thinking/product-sheet/fico-master-file-characteristic-library

Popular Posts

Has the Reporting of Rental Data to the Credit Reporting Agencies (CRAs) Increased?
FICO Score 10T includes rental data, but consumers can only experience the benefit of this to the extent that their rental data is reported to the CRAs
Read more
FICO Statement on FHFA and FHA Updates to Credit Score Modernization
FICO supports FHFA’s announcement that the long-anticipated historical data for FICO® Score 10T will be released to the mortgage market.
Read more
Average U.S. FICO® Score at 716, Indicating Improvement in Consumer Credit Behaviors Despite Pandemic
The FICO Score is a broad-based, independent standard measure of credit risk
Read moreTake the next step
Connect with FICO for answers to all your product and solution questions. Interested in becoming a business partner? Contact us to learn more. We look forward to hearing from you.