Fighting Bias: How Interpretable Latent Features Remove Bias in Neural Networks
FICO’s data science labs called interpretable latent feature-based neural networks (ILF NNET) help expose and eliminate biases derived from data showing up in the model.

One of the biggest challenges of working with data and building predictive models is identifying and handling inherent biases in the data. Here, bias can arise for a number of reasons, including how the data was collected, why it was collected, and simply because bias is inherent in our society. While techniques exist to detect whether a model produces biased results among protected groups, there are insufficient methods to uncover the biased relationships a machine learning model may learn from data or acquire as bias drifts in operation. Knowing these relationships is the first step in understanding how bias manifests in the model, and how to remediate problematic relationships.
Enhancements to a Previous Breakthrough
I’m excited to report that we have developed a method that can automatically surface and triage biases expressed in a machine learning model. This method is a very powerful tool to ensure that Ethical AI development is operationalized, rather than met through luck or, worse yet, unmet and unknown.
Almost three years ago I wrote about an analytic breakthrough developed in FICO’s data science labs called interpretable latent feature-based neural networks (ILF NNET). Our recent work with this method extends ILF NNET, demonstrating that it can help expose and eliminate biases derived from data showing up in the model. Even in cases where the data has been purposely skewed toward one subset of the population over another in the research lab, the method minimizes pick-up of those biased signals versus core relationships that matter. This is largely due to the fact that constraining the latent feature space removes noise and irrelevant correlation, where bias can be expressed.
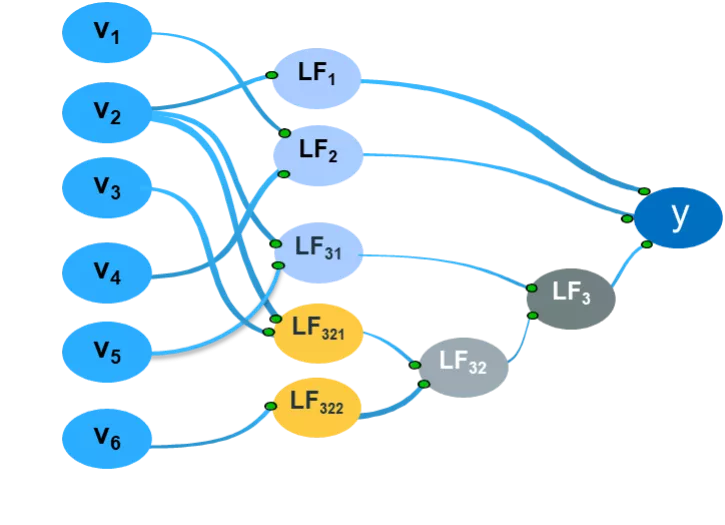
FIGURE 1: An interpretable neural network with hidden nodes (latent features) that can be explained in terms of two or fewer input connections. This approach makes it easy to understand the nature of the learned relationships that the interpretable latent features represent.
Bias Reduction in Action
As a quick refresher, we start with a fully connected neural network as the “base” model and simplify it by the Highlander Principle—there can only be “one best” model—by iteratively resolving hidden nodes to have no more than a specified number of inputs, usually two or less (i.e., an interpretability threshold of two). The resulting interpretable neural network shown in Figure 1 has all its hidden nodes explained in terms of no more than two input connections. This makes it easy for data scientists and business users alike to understand what learned relationships those interpretable latent features represent.
In our study we used well-known adult census data provided by the UCI Machine Learning repository to train predictors to generate binary classification of income groups: over $50,000 or below $50,000. This dataset has been documented to yield biased predictive models if sufficient rigor and care are not applied.
The dataset has 67% men and 33% women; 31% of men are reported to make over $50K and 11% of women are reported to make the same amount. Similarly, in the racial composition, the population is 85% white and 10% Black, with 5% of the over $50K group being Black.
For research exploration, we took this dataset and trained our “base” neural network models both with and without race and gender as predictors. In both the cases, the resulting interpretable latent feature neural networks didn’t choose gender or race as predictors, even when provided to the model as inputs.
In scenarios with and without race and gender as initial predictors for the base models (but ultimately not chosen when presented by the interpretable latent feature model), the resulting interpretable latent feature-based neural network models were quite similar. Here, there were similarities in terms of the latent features they had learned, even though the initial “base” models differed substantially in their structures and parameters. Notably, the base model utilized the protected class inputs, whereas the interpretable latent feature network excluded them in the course of training.
We hypothesize that a fully connected model is “greedy,” using all the available information to associate with the model outcome. On the other hand, the process of regularization employed in sparse neural network training forces weaker relationships to drop off from the model, retaining the strongest, most relevant relationships as predictors. Thus, interpretable latent feature-based neural networks turn out to be good at avoiding learning biased relationships.
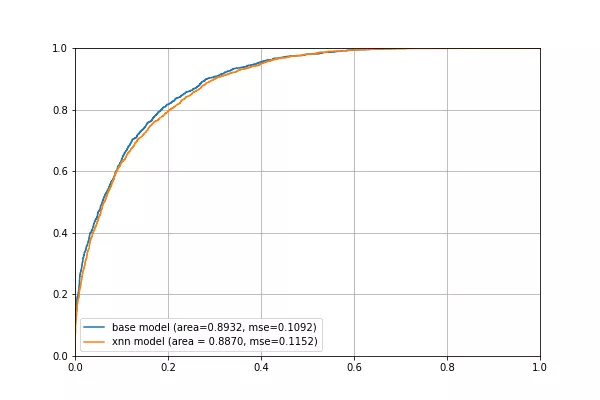
FIGURE 2: Base model with gender and race as input compared to an ILF XNN model in which interpretable latent feature training excluded the use of the gender and race automatically. The resulting ILF XNN model also exhibits very similar model performance.
We additionally wanted to explore whether such models would always guarantee exclusion of biased relationships, and if not, what steps could be taken to ensure such an outcome. So, we skewed even more heavily the training dataset toward some of the protected classes. The resulting model ended up with latent features’ distributional behavior (imputed bias) with respect to different race and gender. This shows that while our method eliminates bias in most cases, it doesn’t guarantee doing so when data is very heavily biased, and allows us to discuss how to address that challenge.
Testing for Inherent Bias
To ensure and test for bias when it ends up existing in the ILF NNET we took a few more steps. First, we looked at the activation of each latent feature for the various protected classes. For example, Figure 3 shows the distribution of activation values of latent feature LF2 for two classes of people, blue people and orange people. The further apart the two curves are, the more the latent feature will have different outcomes on the two classes of people. On the other hand, almost overlapping curves would indicate that the latent feature is indistinguishable between the two classes of people. Thus, different distributions of activation for different protected classes point to the resulting model showing inherent bias in its eventual use in production.
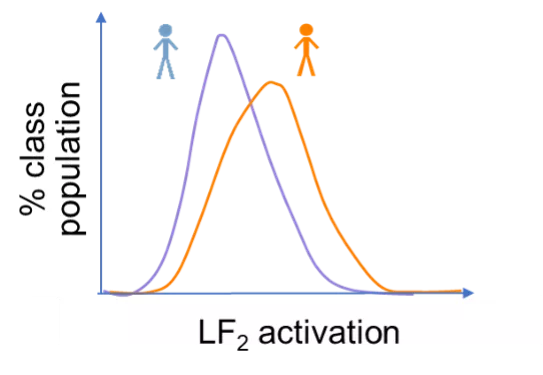
FIGURE 3: A schematic distribution of activation values of latent feature LF2, for two classes, blue people and orange people. Since the distributions are non-overlapping, this latent feature is biased with respect to blue and orange people at the activation level.
A complete review of all the latent features allows us to know which of them induce bias in the model. Once we have identified the offending latent features, our next step is to eliminate interaction between the input variables that constitute these biased latent features.
For example, the latent feature LF2 is defined by v1 and v4 as shown in Figure 1. If this latent feature is determined to have a distributional difference between classes, we can prescribe during constrained neural network retraining not to allow formation of any latent feature with those two input features as incoming connections. By retraining the model to eliminate interactions between v1 and v4, we can ensure that the biased relationship represented by the latent feature LF2 is not learned by the model.
Wash, Rinse, Repeat
Upon retraining with all offending interactions eliminated, we again investigate the latent features in the resulting model. If we identify any latent feature with non-overlapping activation distribution, we eliminate those offending relationships in another iteration of model training in similar manner. This is shown below where we found that the latent features, LF21 and LF23, which resolve the original biased latent feature LF2, have similar activation values across different protected classes. On the other hand, LF22 shows biased relationship. We repeat this process until no biased latent features are left in the consequent model. The final model is an unbiased model.
FIGURE 4: Schematic distribution of activation values of various latent features that resolved the original biased latent feature LF2 for two classes, blue people and orange people. While LF21 and LF23 are not biased, LF22 still shows bias and must be further resolved in the next iteration of model retraining.
The Path to Responsible AI
Our research provides a method to choose machine learning algorithms such as interpretable latent feature models, which generally avoid bias because bias is often not a dominant signal. This forms the basis for using machine learning architectures that minimize unnecessary complexity, which creates space in the variable weights to impute bias.
In rare cases where interpretable neural networks may show disparate distributions of latent features, these can be detected on training data, with explicit non-linearities removed from subsequent retraining. Incorporating formal distributional testing of latent features is unique and gives machine learning scientists a means to tackle bias objectively. Moreover, these same latent features will be continually monitored for bias drift, as part of an Auditable AI process to ensure that the model remains unbiased in the operational environment.
Follow me on Twitter @Scott Zoldi and on LinkedIn to keep up with my latest thoughts on stamping out bias through Responsible AI, Ethical AI, Auditable AI, AI governance and more.

Popular Posts

Has the Reporting of Rental Data to the Credit Reporting Agencies (CRAs) Increased?
FICO Score 10T includes rental data, but consumers can only experience the benefit of this to the extent that their rental data is reported to the CRAs
Read more
FICO Statement on FHFA and FHA Updates to Credit Score Modernization
FICO supports FHFA’s announcement that the long-anticipated historical data for FICO® Score 10T will be released to the mortgage market.
Read more
Average U.S. FICO® Score at 716, Indicating Improvement in Consumer Credit Behaviors Despite Pandemic
The FICO Score is a broad-based, independent standard measure of credit risk
Read moreTake the next step
Connect with FICO for answers to all your product and solution questions. Interested in becoming a business partner? Contact us to learn more. We look forward to hearing from you.