Real-Time Payments Fraud Is Growing - Here's How to Prevent It
As real-time payments take off and begin to dominate ecommerce growth, banks must address real-time payments fraud with sensible friction and personalized notifications

As I sat down recently to try out a new streaming series recommended to me by a friend, I found myself multi-tasking. I was ready to buy something I’d been surfing for with my phone, but my new wallet-free lifestyle meant that I didn’t have any of my physical payment cards ready at hand to complete my purchase.
But right there on the checkout page was the option to complete my purchase using my preferred digital payment option, Apple Pay (the site also offered Google Pay, PayPal, and Stripe). Since I frequently use that payment option, I had my new purchase complete before the title of my new favorite show was off the screen.
It occurred to me right then that the speed and convenience of using one’s phone as a payment tool was having a profound impact on my individual behavior, and consumer behavior in general. It also reinforced why digital wallets and payments have gone from a niche use case to widespread norm in very little time.
Digital Payments: A Customer Experience Must-Have
The integrated digital payment option has become a game changer for ecommerce sites. When I can’t one-click buy on a site the way I can on sites like Amazon or eBay, it’s become a reason not to buy. Sites that don’t prioritize multiple payment options, including digital real-time payments (RTP), can create a negative customer experience that results in lost sales.
While it seems like we’ve waited for years for easy one-click buying, we have crossed a threshold where customers gravitate to this convenience and expect it to make things super easy for them. Worldwide data backs this up — consumers are changing their purchasing behavior because of the unbeatable convenience of real-time payments.
The US Department of Commerce says the global value of ecommerce transactions will grow from $5.9 trillion to nearly $6.4 trillion between 2023 and 2024 alone. It reports ecommerce transactions have grown since 2020 from 18% of all retail commerce to 22% in 2024.
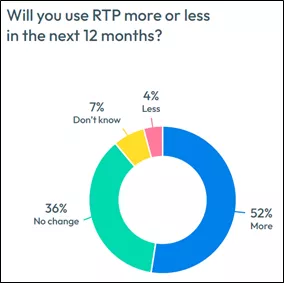
At the same time, global real-time payments are expected to grow more than 30% per year by 2030. FICO’s own research indicates that globally, 88% of consumers plan to maintain or increase individual use of RTP. It’s a sea change in the payments landscape that is not going away, and if my career in fraud management has taught me anything, it’s that fraudsters will follow the money. So what can we do to help detect and prevent fraud in these growing payments methods?
Payment Fraud Management Must Be Up to the Task
As consumers and merchants both embrace digital RTP, banks need to make sure their fraud prevention capabilities for real-time payments can operate at the same level of proficiency they have achieved for their credit and debit card transactions – and do it while the RTP transactions multiply fast. Let’s examine some of the key management steps banks can take in this rapidly changing landscape to ensure best-in-class fraud detection and prevention:
Establish the New Baselines for Detection
The first step is recognizing that customers are using different types of payment channels to move funds in and out of their accounts. We know fraudsters are already onto this change; scams grew 30% between 2021 and 2022 in the US and more than 40% of all fraud loss in the UK came from real-time payments fraud in 2022.
For banks, it’s crucial to monitor and measure these behaviors and establish new behavioral baselines very quickly. Given the growing transaction volumes, there should be plenty of live data. With continued monitoring, a bank can flag anything that looks abnormal and determine if it signals fraud.
Add Sensible Friction
Fraudsters have been early adopters of RTP because they can get funds quickly and irrevocably from unsuspecting consumers. FICO research shows that globally, 68% of consumers have gotten some sort of outreach they thought was part of a scam, which illustrates just how pervasive the problem has become.
Because consumers, not banks, represent the primary target for scams, the next key step is to add more sensible friction into payment processes. Because RTP methods allow for immediate transfers of life-changing sums of money, putting any small amount of friction into the process can potentially help prevent scam losses. Adding an “Are you sure?” screen with a clear scam warning can help customers think a bit before sending cash to a thief.
Enable Personalized Notifications
The next key step to prevent fraud in digital payments and RTP is to enable customers to customize notifications at any and every step in the process. Banks can also allow customers to receive communications to their preferred channel — email, mobile, social, bank app, or messenger app.
This way, a fraud attempt or fraudulent payment cannot happen without the customer being notified that something has transacted against any of their accounts, cards, or loans. When a bank provides this level of personal communication, it gives customers the tools they need to expand their trusted relationship and protect themselves from emerging scams or other forms of fraud.
Balancing RTP Growth and Fraud Management
Consumers will continue to embrace the convenience and speed of digital and real-time payments. This will in turn raise the customer experience and fraud management demands on financial institutions. Banks will have to recognize these new payments channels are simply additive and will not completely replace the risks and fraud schemes of established payments methods like checks or credit and debit cards.
In fact, RTP will just add new twists to enterprise fraud management. As a result, financial institutions need to continue to understand who their customers are, establish what their evolving behavioral baselines look like, define what actions to take when abnormalities happen, and know how the customer prefers to be contacted when necessary.
The root solution to defending customers and all their payment channels comes back to the same concepts — knowing what normal looks like, acting when something happens that isn’t normal, and communicating as much as possible though sensible friction and personalized notifications and alerts.
How FICO Helps Detect and Prevent Payments Fraud
- Explore FICO’s innovative fraud protection technology
- Learn how real-time customer communications can help stop fraud
- Read about FICO’s award winning, machine learning-powered retail banking model with scam detection score
- Download the FICO 2023 Scams Impact Survey
For more of my latest thoughts on the evolution of payments, fraud, and FICO’s entire family of software solutions, follow me on LinkedIn.

Popular Posts

Has the Reporting of Rental Data to the Credit Reporting Agencies (CRAs) Increased?
FICO Score 10T includes rental data, but consumers can only experience the benefit of this to the extent that their rental data is reported to the CRAs
Read more
Average U.S. FICO® Score at 716, Indicating Improvement in Consumer Credit Behaviors Despite Pandemic
The FICO Score is a broad-based, independent standard measure of credit risk
Read more
FICO Statement on FHFA and FHA Updates to Credit Score Modernization
FICO supports FHFA’s announcement that the long-anticipated historical data for FICO® Score 10T will be released to the mortgage market.
Read moreTake the next step
Connect with FICO for answers to all your product and solution questions. Interested in becoming a business partner? Contact us to learn more. We look forward to hearing from you.