Improving IRB and RWA Calculations with Machine Learning
Through explainable machine learning models, behavioural and PD models for the retail banking sector can be created with higher levels of predictiveness.

Traditional scorecards have been the backbone of IRB expected capital loss calculations for years, but could advances in machine learning provide better models and reductions in IRB and RWA calculations?
In November 2021, the European Banking Authority (EBA), the prudential arm of the European Union, issued a discussion paper on the use of machine learning in IRB models. This was predicated on advances in explainability of machine learning models (e.g., for tree ensembles) helping to address some of the challenges that such complex models create. As the introduction to the discussion paper puts it:
“Whereas standard regression models may not be able to keep track with the emergence of the so called ‘Big Data’, in fact, data is the fuel that powers ML models by providing the information necessary for training the model and detecting patterns and dependencies. This does not come without costs; indeed, ML models are more complex than traditional techniques such as regression analysis or simple decision trees, and often less ‘transparent’.”
Here at FICO we’ve been exploring for almost a decade the use of explainability in machine learning through our xAI technology (check out Scott Zoldi’s post on Using Machine Learning in Credit Risk Models) which is now embedded in FICO Platform. Through our explainable machine learning models, behavioural and PD models for the retail banking sector can be created that provide higher levels of predictiveness coupled with explainable outcomes and reason codes.
Do Machine Learning Models Bring Predictive Improvements?
To test whether using machine learning for PD models would have a significant impact on expected capital loss for banks, we used some research data from a previous IRB model build for a Eurozone bank. The original model structure had three PD model segments predicting default at the exposure level. We built explainable Gradient Boosted PD models for each of these three segments, with exactly the same input variables and generated characteristics as the previous scorecards.
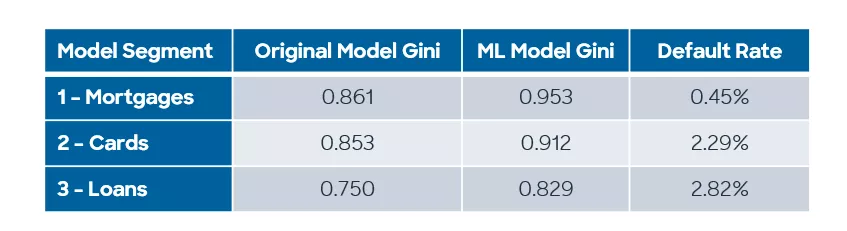
As might be expected for a behavioural model with already high Gini values, there were minor improvements in predictability across the four segments, but nothing overly dramatic. We have, however, demonstrated the power of Gradient Boosted models and managed to produce an improved Gini with just one model over the entire data rather than four segments. Straight away there are definite future cost savings in model development and monitoring to be had by this approach.
What Is the Impact on PD and RWA?
Although the Gini improvements are modest, in the background we are producing a subtle shift in the PD distributions for the better. In particular, we find that the machine learning models produce a smoother distribution of score values, giving us a better spread and allowing low risk to be emphasised. This has a knock-on impact in the subsequent RWA calculations.
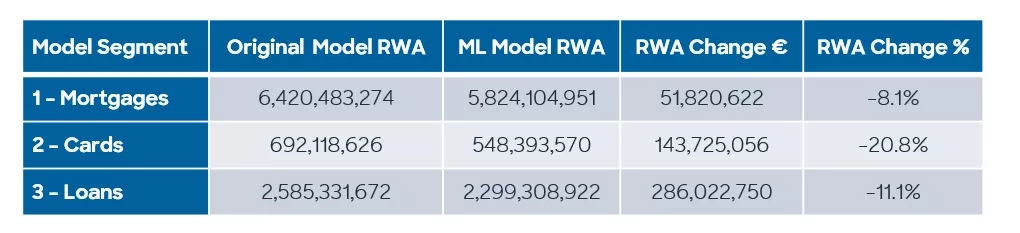
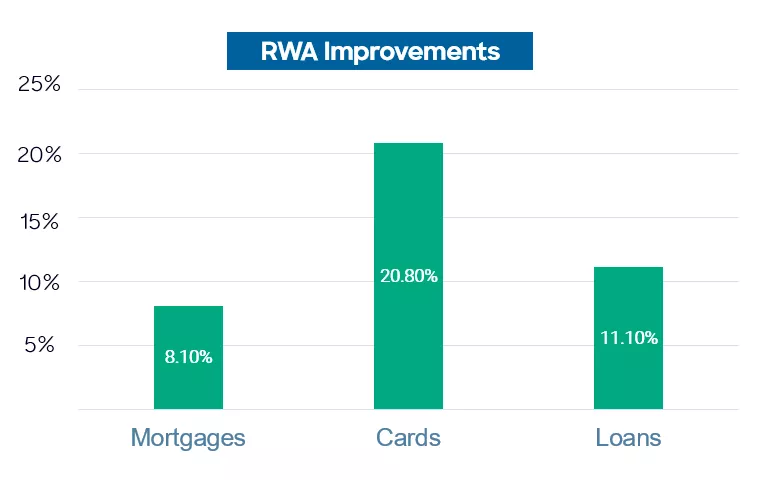
Now the results are dramatic and show the power of the machine learning models. The larger portfolios with better data sets can take advantage of the volume of information to produce better discrimination, which spreads out the PD values better. By moving large volumes of accounts to lower PD, there is a significant reduction in RWA values, which can be reflected in the final expected capital loss values.
Conclusion
The initial results are therefore extremely promising – a significant reduction in RWA from an improvement in discrimination, powered by more advanced models that are able to produce more power from the large data sets that are typical of IRB model builds.
In my next blog post, I’ll look at how we can use the power of FICO Platform to perform similar analysis on any IRB portfolio, and crucially, use FICO’s xAI technology to provide explanations at an individual exposure or obligor level.
With thanks to my colleagues Priyanka Roy and Ramanuj Bagchi
How FICO Can Help You Improve Loss Calculations

Popular Posts

Has the Reporting of Rental Data to the Credit Reporting Agencies (CRAs) Increased?
FICO Score 10T includes rental data, but consumers can only experience the benefit of this to the extent that their rental data is reported to the CRAs
Read more
FICO Statement on FHFA and FHA Updates to Credit Score Modernization
FICO supports FHFA’s announcement that the long-anticipated historical data for FICO® Score 10T will be released to the mortgage market.
Read more
Average U.S. FICO® Score at 716, Indicating Improvement in Consumer Credit Behaviors Despite Pandemic
The FICO Score is a broad-based, independent standard measure of credit risk
Read moreTake the next step
Connect with FICO for answers to all your product and solution questions. Interested in becoming a business partner? Contact us to learn more. We look forward to hearing from you.