Rank Distillation: Operationalizing AI Continuity in the Corpus AI
New models can underperform alarmingly easily if you take your eyes off the Corpus AI


Decision management systems are complex, consisting of numerous components such as machine learning (ML) models, decision strategies, rules systems, alert management and performance monitoring. Too often, machine learning is the focal point, but the ML model is only one component of the much larger enterprise analytic body, the Corpus AI. Moreover, the data scientists who build the ML models are often far removed from the people who distill and determine decisioning strategies, implement rules systems, or triage the decisions of the Corpus AI. To address this disconnect and truly operationalize AI, guardrails must be in place such that the overall Corpus AI continues to perform while components change. Rank distillation is one of the methods – read on to learn more about this important data science method.
Retraining ML Models: The Care and Feeding of AI Systems
All AI systems need to have their machine learning models updated, strategies adjusted and the effectiveness of rules systems assessed – how successfully are the decisioning system and methods meeting the business objective? Model retrains are one of the major components that effect change, since the ML models are the predictive and detection components of the Corpus AI, and directly drive other decision components downstream.
Naively executed, a retrained ML model will improve but may accentuate different behaviors compared to the prior model. This results in substantive changes in different customer behaviors moving between different model score bands – even if the overall model delivers better global prediction. The challenge becomes, then, that the strategy, methods and rules systems are tuned to the old model’s behaviors within a score band. How can this be rectified?
The Risks of Retraining
For example, perhaps the AI operator is satisfied with the detection of cross-border ATM fraud at a score threshold of 800, and with dollar-value rules that block transactions at $200 when both the score and dollar thresholds are met. In the new model, perhaps the same behavior now generates a score of 600; without modification, the rule would not capture the same volumes of this event, resulting in lower case volumes and less efficacy in overall fraud detection.
Since AI systems have hundreds, sometimes thousands of rules, impedance mismatches between the old and new models’ scoring of the same behaviors can add up to a highly performant model upgrade, but a poorly performing AI decisioning system – more bluntly, a “great model, but bad decisions.” As such, we need to be able to quantify the impact of a model retrain on the full Corpus of AI and minimize the behavior impedance mismatch.
Rank Distillation Smooths the Transition from Old Model to New
Fortunately, it is well known that there is not one model solution, but a huge number of solutions when we train models. The trick is how to select the solution that minimizes behavior impedance mismatches across the dataset, so rules continue to be effective. Figure 1 below represents this scenario in a schematic.
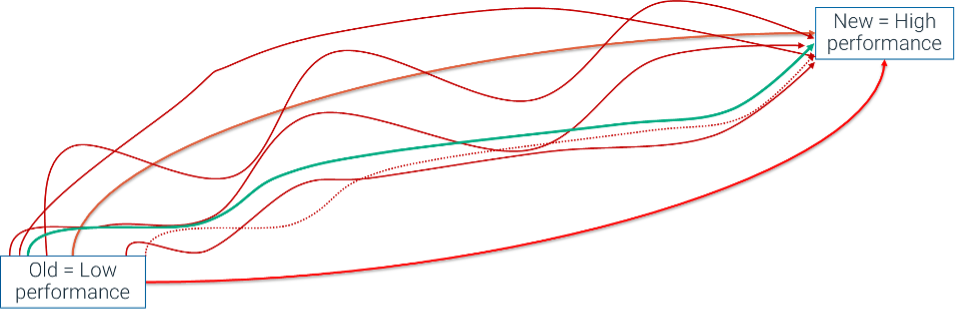
Fig. 1. There are many paths to achieve higher model performance.
Simply put, a customer should not have a significantly different score or AI decisioning system outcome because one of the multitude of solutions in Figure 1 is chosen over another. Similar behaviors should be expressed by both models. While the newer model has better detection capability, it needs to be constrained to understand that it, in fact, finds performance lift without completely disrupting the Corpus AI, and ultimately the realization of that value in decisioning.
The method FICO has used to achieve this is called score rank distillation. Rank distillation constrains the ML model to a solution that minimizes differences between old and new model scores for similar behaviors. The resulting new model then requires fewer adjustments in the downstream business decisioning strategies and rules of the Corpus AI.
A Student Model - Teacher Model Approach
Conventional supervised machine learning uses a loss function for model training that optimizes classification performance only on the new data, without any insight into the old model’s behaviors that it is intended to replace. In this rank distillation approach, the loss function penalizes large deviations in the new model’s predicted output compared to the old model’s prediction; simultaneously, it also optimizes detection performance of the new model on ground-truth target values. The old model is used as a teacher model and the newly trained model is the student model.
Given multiple, equally fit models, the one that minimizes disturbances to treatments of customers based on score difference between old teacher model and new student model is preferred. Figure 2 below shows the performance of the model trained using conventional loss function alongside another model trained using our novel loss function.
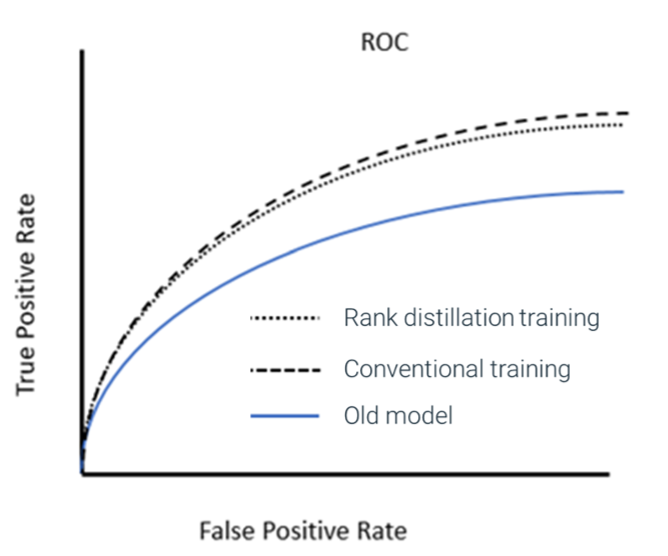
Fig. 2. Both the model trained using conventional loss function and the model trained with FICO’s ranked distillation provide similar lift in performance compared to the original model. Note: This figure shows only theoretic value; it does not measure the conventional training to be more misaligned with the rules/strategy of the existing Corpus AI, which ultimately lowers the decision performance metric.
Figure 2 shows an important myopic nuisance, although conventional training looks slightly superior to the rank distillation training. If the behaviors in high-scoring cases for the conventional model are significantly different than the old model, then the slight lift in the conventional training (above) is never achieved. In fact, overall decisioning system performance can dramatically fall below the rank distillation model due to the behavior impedance mismatch and its negative impact on the rest of the Corpus AI.
How Often Do New Models Deliver Less Performance?
New models can underperform alarmingly easily if you take your eyes off the Corpus AI. A dataset comparison of the top 1% of cases generated by the new conventional fraud model to the top 1% in the old fraud model showed that 150% more chip fallback cases were flagged in the new model. But with the rank distillation approach, the new model yielded a similar number of chip fallback transactions in the top 1% compared to the old model. (Figure 3)
Since the strategy and rules systems will not adjust to drastic swings in case numbers (without entire studies and an overhaul of strategy/rules), using the new conventionally trained model will result in a larger number of false positives, due to the Corpus AI making decisions based on interplay between model scores and decisioning rules. This can prevent realizing the new model’s value, or worse, result in a perhaps-lower overall decision performance of the Corpus AI due to the impedance mismatches.
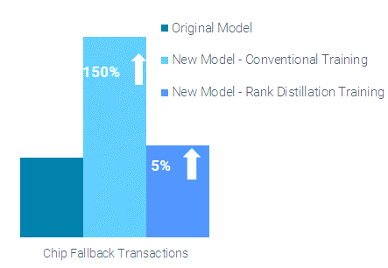
Fig. 3. Relative frequency of chip fallback transactions in the top 1% cases generated by original model, and the newly trained models using conventional and rank distillation approaches. The conventionally trained model produced 150% more chip fallback cases in the top 1% of cases but the rank distillation model produced only 5% more, resulting in more stable model behavior and less impact to the Corpus AI decisioning rules and outcomes.
Key Takeaways
Here are three key learnings that data scientists and business people can use to better operationalize AI decisioning systems:
- Rank distillation models choose model training that treats customers not too differently than in the old model. This results in less disruption than from unconstrained model updates that are not sensitive to the rest of the Corpus AI.
- Conventional training may at times look better on only model training data, but without a view to the entire Corpus AI, “better” may not be realized in value as established strategies, methods and rules change slowly or not at all.
- Machine learning models can be constrained to be good citizens in the Corpus AI by reflecting and prioritizing two benefits: minimal operational disruption and customers receiving correct outcomes when the model is used to distill appropriate actions in the overall Corpus AI system.
Keep up with my latest thoughts on data science and Responsible AI by following me on LinkedIn and Twitter @ScottZoldi.

Popular Posts

Has the Reporting of Rental Data to the Credit Reporting Agencies (CRAs) Increased?
FICO Score 10T includes rental data, but consumers can only experience the benefit of this to the extent that their rental data is reported to the CRAs
Read more
Average U.S. FICO® Score at 716, Indicating Improvement in Consumer Credit Behaviors Despite Pandemic
The FICO Score is a broad-based, independent standard measure of credit risk
Read more
FICO Statement on FHFA and FHA Updates to Credit Score Modernization
FICO supports FHFA’s announcement that the long-anticipated historical data for FICO® Score 10T will be released to the mortgage market.
Read moreTake the next step
Connect with FICO for answers to all your product and solution questions. Interested in becoming a business partner? Contact us to learn more. We look forward to hearing from you.