From Detection to Prevention – Tackling Scams from Every Angle
As real-time payments continue to grow globally, authorized push payment fraud scams follow. making intervention imperative

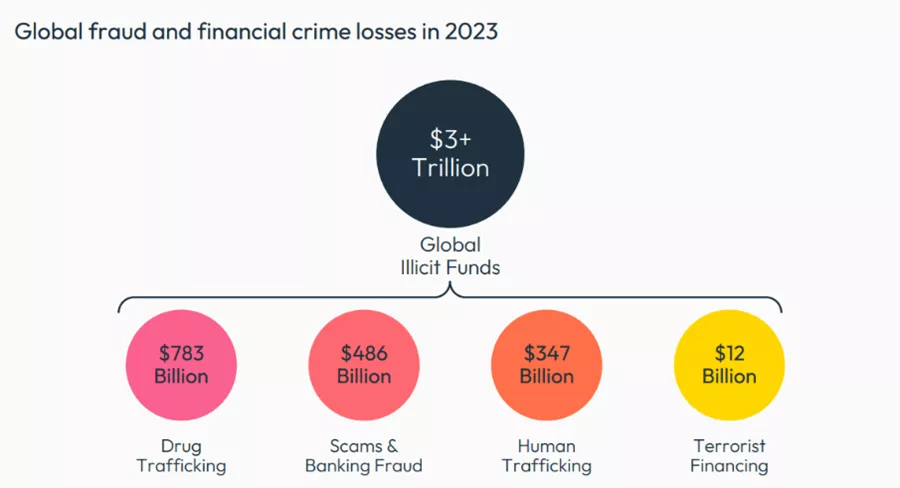
A recent NASDAQ financial crime study revealed that of the $3 trillion in illicit funds processed last year, approximately $486 billion could be attributed to scams and fraud. They continue to evolve and slip through the systems being developed to stop them.
At FICO World 2024, FICO expert Naomi Palmer and I explored the underlying factors enabling the success of scams and the strategies needed to stay ahead of them.
The Psychology and Economic Factors Behind Scams
Scammers leverage human psychology to exploit victims during their most vulnerable moments, explained Naomi. Most individuals are familiar with the typical warning messages from banks, advising against sending money to unknown contacts. These messages can work when our brains are in a ‘cold state’ where we are in control and not as vulnerable. However, when people find themselves in a ‘hot state’ — emotionally charged moments, such as the thrill of a slot machine win or the urgency of Black Friday sales — they become more susceptible to scams. Fraudsters are expert at social engineering, creating a sense of urgency, making it difficult for potential victims to resist and easier for fraudsters to manipulate them.
I highlighted that several economic factors have created the perfect storm, leading to increased financial crime and more individuals falling victim to scams.
The ongoing fallout from the COVID-19 pandemic, a persistent cost-of-living crisis, and global conflicts have heightened financial strain for many individuals. More people feel compelled to either participate in fraud as a quick means of income or have become targets themselves. There are three main components at work here:
- Motivation: The desire to get rich quickly or the need to support a family can push individuals toward fraudulent activities.
- Opportunity: Technology has created unprecedented opportunities, enabling criminals to operate from anywhere with minimal risk.
- Rationalization: Individuals often convince themselves that their actions are justified, viewing fraud as a necessity rather than a crime.
Technology – a Double-Edged Sword
While industries rave about the benefits of significant advancements in technology, these same advancements are making it easier for criminals to execute their schemes from virtually anywhere and with the appearance of legitimacy, according to Naomi. For instance, fraudsters now utilize sophisticated tools like deep fakes and voice cloning to enhance their deception.
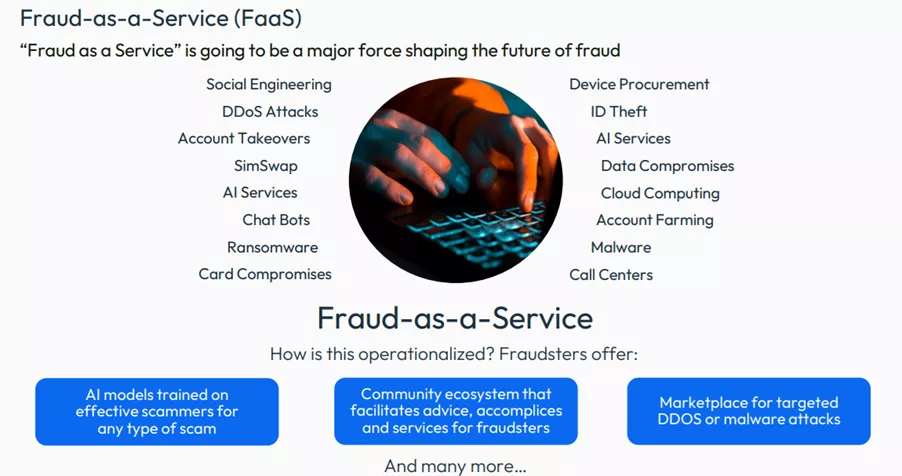
Organized crime rings are now employing models akin to ‘fraud as a service’, where various services related to fraud—such as malware and identity theft—are offered on the black market. This has transformed the nature of fraud, allowing even amateur criminals to access tools and strategies that were previously available only to seasoned professionals.
Regulatory Responses and Solutions
In light of the growing threat of fraud, regulators have stepped up their efforts to address the issue. This is driving greater collaboration between financial institutions, telecommunications providers, and law enforcement agencies to share data and improve fraud prevention efforts. Three key themes have arisen from this increased focus:
- Consumer empowerment: Helping victims recognize potential fraud through alerts and education. For example, confirmation of payee systems to help individuals ensure they’re sending money to the correct recipient.
- Data sharing: Enhancing communication and information sharing between financial institutions and relevant organizations to create a more comprehensive approach to fraud detection.
- Liability shifts: Some countries are implementing legislation to share liability for fraud losses, ensuring that multiple parties take responsibility for protecting consumers.
Building Fraud Prevention into the Customer Life Cycle
There are many stages to a scam, beginning at originations, when for example a mule account is created, developing right through to the point a payment is made. Fraud prevention, therefore, needs to be a critical consideration at every stage of the customer lifecycle.
As well as at the account opening phase, verifying customer identity is essential as an ongoing process with methods like passive authentication, which can prove critical for detecting red flags in behaviors that deviate from the norm.
Once a customer is onboarded, transactional fraud monitoring plays a key role in protecting both the customer and the bank. However, with scams constantly evolving, these monitoring tools must continue to evolve as well.
It shouldn’t stop there. Other tools are needed to connect the dots from the point of origination all the way through the payment itself. By using tools like entity profiling and link analysis, patterns across different fraud cases can be identified, helping banks detect organized crime rings.
Communication with customers is also vital. While it does exist throughout the lifecycle, where fraud is concerned it shapes their perception of the bank’s security and builds trust.
It’s worth noting that fraud prevention efforts generate valuable data about customer behaviors, which can be used to help grow relationships and reduce onboarding friction for future products while preventing fraud. Connecting the dots between customer interactions and transactions allows for a comprehensive approach to fraud prevention, protecting both customers and banks.
Three Key ‘Must Haves’ in the Fight Against Scams Today
Scams pose significant challenges for all organizations, but there are three essential components for effective fraud detection and fraud prevention that can be implemented today.
- The latest scam detection models, such as FICO's latest retail banking model, which distinguishes between general fraud and scam-focused threats, allowing for tailored prevention strategies. Otherwise, organizations will find themselves trying to fight new and emerging scams using tools designed to address general fraud scenarios.
- Data to confirm if scam activity is likely, while models can detect likely fraud taking action to intervene with the customer or even stop the payment requires a level of confidence that fraud is in progress. Bringing data sources together that provide a more rounded view of what is happening is vital to turning detection to prevention. FICO has been working with our partner Jersey Telecom on an award-winning scams signal that uses telco data to reinforce decision making for scams prevention.
- Identity resolution and link analysis involves consolidating data from various sources to create a comprehensive view of individuals and their activities. By understanding connections between entities, organizations can identify potential fraud patterns and react swiftly.
- Omnichannel communication is a move beyond traditional messaging methods. It is dynamic, automated and tailored communication strategies to focus on the specific scam type and to break the manipulative spell cast by fraudsters.
We concluded that the goal is not to overhaul existing systems, but to complement them, so that organizations can keep evolving their strategies as quickly as their counterparts in the criminal world.
How FICO Helps Detect and Prevent Scams
- Learn how FICO helps financial institutions prevent scams
- Explore how Dock has used real-time customer communications to stop more fraud.
- Read about FICO’s award winning, machine learning-powered retail banking model with scam detection score
- Download the FICO 2023 Scams Impact Survey

Popular Posts

Has the Reporting of Rental Data to the Credit Reporting Agencies (CRAs) Increased?
FICO Score 10T includes rental data, but consumers can only experience the benefit of this to the extent that their rental data is reported to the CRAs
Read more
FICO Statement on FHFA and FHA Updates to Credit Score Modernization
FICO supports FHFA’s announcement that the long-anticipated historical data for FICO® Score 10T will be released to the mortgage market.
Read more
Average U.S. FICO® Score at 716, Indicating Improvement in Consumer Credit Behaviors Despite Pandemic
The FICO Score is a broad-based, independent standard measure of credit risk
Read moreTake the next step
Connect with FICO for answers to all your product and solution questions. Interested in becoming a business partner? Contact us to learn more. We look forward to hearing from you.