Trusted AI: The Challenge of Monotonicity and Palatability
In part 1 of this series, I explore why it's vital - and difficult - to achieve monotonicity and palatability in certain AI models

No matter how much I evangelize critical strategic issues like AI governance, I am always an analytic scientist at heart. In this post I’ll share key machine learning (ML) techniques we’ve developed at FICO to ensure monotonicity in neural networks.
Monotonicity is essential to build trust in decision models used in regulated industries such as lending. Here’s the connection: monotonicity helps ensure palatable (reasonable and acceptable) model behavior, an absolute requirement for gaining the confidence of lenders, customers and regulators in the machine learning models deployed in today’s financial decisioning environments.
What Is Monotonicity?
In an analytic model, a monotonic relationship occurs when an input value is increased and the output value either only increases (positively constrained) or only decreases (negatively constrained), and vice versa. For example, if the ratio of payment to balance owed on a loan or credit card increases, we would expect that the credit risk score should improve (lower risk of default). Figure 1 shows a positively constrained monotonic relationship between these two variables.
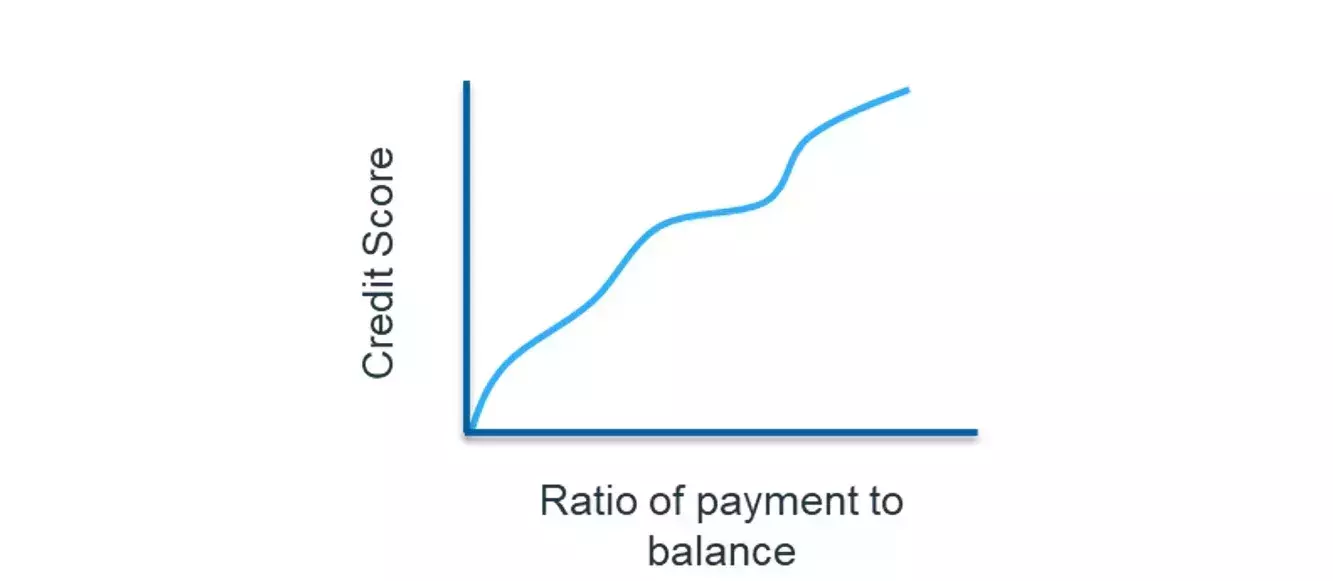
Figure 1: A positively constrained monotonic relationship
What Exactly Is Palatability?
When using decision models in industries like lending, banks often need to demonstrate their palatability (reasonable and acceptable behavior) to a regulator. Palatability, a fuzzy gray concept, can be difficult to achieve with machine learning models if the training algorithms are not constrained. To demonstrate palatability we need to first, as always, show that the internal learned model features are not biased. This requires an ability to demonstrate nonlinear relationships learned by the machine learning model. Second, we show that the model behavior is reasonable, given changes in the model inputs.
With “black box” machine learning models, demonstrating palatability becomes even more difficult. To address this challenge, many decision models historically utilize “white box” models such as scorecards, which are transparent. Specifically, scorecards demonstrate, in a straightforward and definitive manner, how each input variable is related to the final decision, and how monotonicity can be enforced in the design of the model features and associated weight of evidence as the feature values change.
However, despite these advantages of scorecards, their data scientist proponents are increasingly aware of the need to use more machine learning to drive higher decisioning performance. Thus, the rub: with traditional machine learning models it’s often impossible, other than by dumb luck, to have a fully monotonic model. To meet monotonicity requirements we need to apply constraints. It’s a critical step because, historically, a lack of decision transparency and palatability has impeded machine learning model adoption.
Neural Networks Boost Predictive Power - and Complexity
Neural networks can bring tremendous additional predictive power to decision models. In our experience at FICO, neural networks can meet or exceed the predictive performance of the most carefully built scorecards – with development times of up to 40x faster. This eye-popping acceleration is due to the neural network’s machine learning model learning new (and often unanticipated) ways to combine variables, and finding hidden (latent) features in the data which drive increased business value.
Monotonicity is inherently more difficult to demonstrate in a neural network, a complex structure that, as it’s trained, explores the latent feature space of data relationships. Even the simplest neural net, with a single hidden layer, can be very hard to understand.
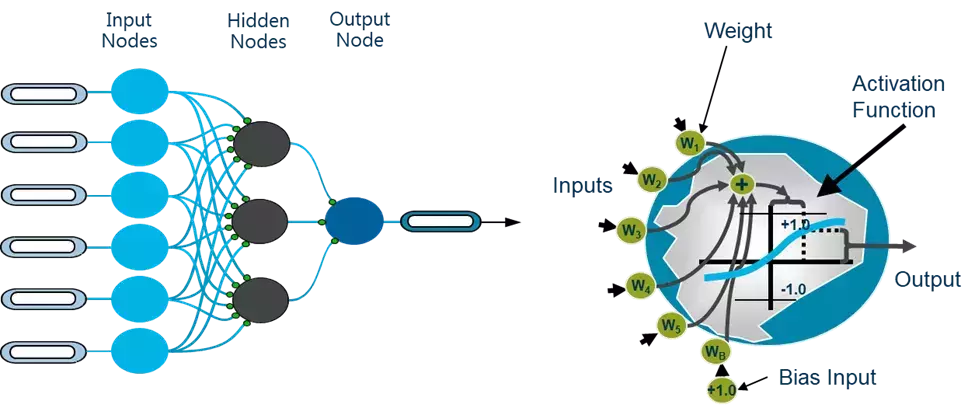
Figure 2: In a fully connected neural network architecture, input nodes (predictive variables) combine in multiple hidden nodes. Each of these multiple hidden nodes represents a hidden relationship, or latent feature.
Bringing Explainability to Latent Features
FICO has addressed the challenge of extracting explainable latent features from neural networks with the invention of Interpretable Latent Features neural networks. To address explainability in a neural network, we constrain the training process to ensure that latent features are at most one or two inputs. This allows us to isolate each learned latent feature relationship to determine if it is palatable, and test it to make sure it’s unbiased. Next, we ensure monotonicity of the output of the neural network, given changes in values of input variables.
Other data science organizations have tried to achieve monotonicity through brute-force exhaustive search and testing. This does not guarantee an optimal solution and, at the same time, consumes a tremendous amount of compute time and resources. A data scientist may not come across features that are truly monotonic as they march through permutations of architecture and training seeds.
How FICO Achieves Monotonicity
FICO has continued working in explainable neural network technology to impose monotonicity requirements on inputs and outputs. We accomplish this by putting additional constraints on the training of the neural networks, guaranteeing a computationally efficient (and convergent) solution with the desired monotonicity constraints. Our approach leverages the same gradient descent-based optimization approach for training the neural network, and as such it also guarantees the best fit model.
Gradient descent-based optimization? You guessed it – we are headed in deep data science territory! Follow me on Twitter @ScottZoldi and on LinkedIn to know when Part 2 of this post is published.

Popular Posts

Has the Reporting of Rental Data to the Credit Reporting Agencies (CRAs) Increased?
FICO Score 10T includes rental data, but consumers can only experience the benefit of this to the extent that their rental data is reported to the CRAs
Read more
FICO Statement on FHFA and FHA Updates to Credit Score Modernization
FICO supports FHFA’s announcement that the long-anticipated historical data for FICO® Score 10T will be released to the mortgage market.
Read more
Average U.S. FICO® Score at 716, Indicating Improvement in Consumer Credit Behaviors Despite Pandemic
The FICO Score is a broad-based, independent standard measure of credit risk
Read moreTake the next step
Connect with FICO for answers to all your product and solution questions. Interested in becoming a business partner? Contact us to learn more. We look forward to hearing from you.