How to Use Alternative Data in Credit Risk Analytics
Here is useful information on how to assess alternative data and combine it with traditional data to improve credit risk analytics

Key Takeaways
- Alternative data is any data not directly related to credit behavior. With 1.4 billion adults worldwide lacking credit records, this is the most important frontier for lenders looking to expand their addressable market without taking on unquantified risk.
- Not all alternative data is equal. FICO evaluates every source against a six-point test covering regulatory compliance, depth of information, coverage, predictiveness, additive value and accuracy before any source makes it into a production model.
- Transaction data is the most underutilized alternative data source lenders already own. Mining it properly can increase available predictive features by 3,000% yet most lenders use only monthly summaries instead of extracting the full signal from spend ratios, transaction frequency and retailer-type patterns.
- Alternative data adds the most value when combined with traditional data, not used as a replacement. Combining both types of data produces a materially stronger model than either source achieves alone.
- Machine learning unlocks unstructured alternative data but must be paired with explainability and ethical guardrails. FICO's Responsible AI standard requires every AI-driven credit model to be robust, explainable, ethical and efficient, to ensure fair consumer outcomes and regulatory compliance.
Incorporating alternative data in credit risk assessments continues to be a very relevant and evolving topic, largely because of sustained focus on financial inclusion, the clear preference from both customers and lenders for quicker, lower friction processes and an ongoing expansion of data sources.
Here is useful information on how to assess and analyze alternative data and combine it with so-called traditional data to both improve credit risk analytics and customer processes.
Multiple Types of Alternative Data Used in Credit Risk Analytics
What is alternative data? In credit granting, it generally refers to any data that is not directly related to a consumer’s credit behavior. Traditional data usually means data from a credit bureau, a credit application or a lender’s own files on an existing customer - this is the data most commonly used in credit scoring models. Alternative data is everything else — a variety of data sources and techniques.
There are an estimated 1.4 billion adults worldwide who don’t have credit and so don’t have credit records. Opening up that market is a priority for lenders. And while many of these consumers are in developing markets with nascent credit infrastructures, there are so-called “credit invisibles” even in the most mature credit markets, people who have no credit and are unknown to the credit bureaus.
At FICO, we are always exploring what alternative data sources can enhance the accuracy and predictiveness of our solutions and help more people gain access to credit. We also recognize that not all alternative data is created equal. When evaluating potential alternative data sources, we are also guided by the application of a six-point test that covers regulatory compliance, depth of information, scope and consistency of coverage, predictiveness, additive value, and accuracy.
With this in mind, let’s look at a few sources of alternative data, and how useful these datasets can be for lenders’ credit decisions.

- Transaction Data. This is typically data on how customers use their credit or debit cards. It may not seem “alternative” — most lenders have this data already, often manipulated into monthly summaries — but it’s not often mined to extract the maximum predictive value. It can be used to generate a wide range of predictive characteristics such as Ratios of Cash to Total Spend in last X week(s) or Ratios of Spend in last X week(s) to last Y week(s) and even characteristics based on the number, frequency and value of transactions at different retailer types. Processing this dataset can be time-consuming, but the data itself is generally well structured and the rewards are significant. Adoption of transaction data for scoring purposes has been reported to enable the creation of additional features that increase the amount of data available by 3000%.
- Telecom / Utility / Rental Data. This dataset is basically credit history data, but it’s alternative because it doesn’t actually appear in credit reports for many markets. In the United States, while the FICO® Score considers telecom and utility data to the extent it is available in the traditional credit bureau data (and more recent versions of the FICO® Score also consider rental data), FICO® Score XD incorporates any additional phone and utility provider payment history not found in the traditional credit bureau data.
- Clickstream Data. Web analytics can provide lenders with additional insights. For example, how a consumer or applicant moves through their website, where they click and how long they take on a page can be predictive. An intuitive use of this data is within the identification of customers who are in financial distress, but who have not yet declared themselves as such to a bank’s representative. If it can be seen that a customer has been accessing any content on your website relating to financial support, then this can be used to support and inform your early warning / pre-delinquency activity.
- Audio and Text Data. This data takes the form of information found on credit applications, in recorded customer service or collections calls. It can complement “thin” credit report files and is already proving its worth in collections, where it can support the identification of additional hardship or vulnerability cases. A common but often overlooked use of this data is also within the compliance function, where AI now makes it possible to screen and assess every call or interaction. This supports not only deeper analytics that ensure the compliance of your decision strategies – but also the identification of both strong and weak agent engagements with customers.
- Social Network Analysis. Technology now enables us to map a consumer’s network in two important ways. First, this technology can be used to identify all the files and accounts for a single consumer, even if the files have slightly different names or different addresses. This gives you a better understanding of the consumer and their risk. Second, we can identify the individual’s connections with other people, such as people in their household. When evaluating a new credit applicant with no or little financial history, the credit ratings of the applicant’s network can provide useful information. However, this dataset is not going to meet the regulatory tests in all markets.
- Survey / Questionnaire Data. An innovative technique, this analysis allows lenders to rate the credit risk of someone with little or no credit history through psychometrics.
- Open Finance. Greater clarity regarding your customers’ finances is becoming available through the ever-expanding open finance universe. Savings and investment data can now be made available to lenders digitally, through 3rd party platforms, whilst Open Payroll providers are also appearing. These support creation of a more detailed customer view and efficiency of process. An example in the US would be the UltraFICO Score, which analyzes consumer-permissioned data from checking, savings or money market accounts.
- BNPL / Embedded Finance. Consumer preferences are changing quickly, making the use of BNPL services a significant growth area. The expectation is that this market will reach $7.2 trillion in size by 2030. Consequently, there is a concerted effort from credit bureaus to ensure this data is available for lenders.
How Much Value Does Alternative Data Add?
The value of this data is typically realized through improved process efficiency and analytics.
The importance of the efficiency point should not be overlooked as FICO research has shown that 88% of consumers value the experience provided by the financial services providers, as much as the products and services. A key differentiator, which can make or break the relationship with a customer, is the ability to provide low friction experiences, across the customer lifecycle. Access to digitized data that removes the need for documents to be provided or lengthy phone calls is key for providing these experiences. Banks recognize the importance customers place on this, and the benefits it can bring to the efficiency of their operations, as reflected by a survey of mortgage providers in the UK, that showed an almost universal desire to support more efficient underwriting processes with more data.
The improvements these data sources can bring to the predictive value on margin to risk models, has also been clearly proven by FICO research. The amount of predictive value outlined in the table below should be viewed as relative indicators, not absolute values, as the additional value of the data source is based on many parameters such as predictive power of existing models, strength of the customer relationship with the lender, etc.
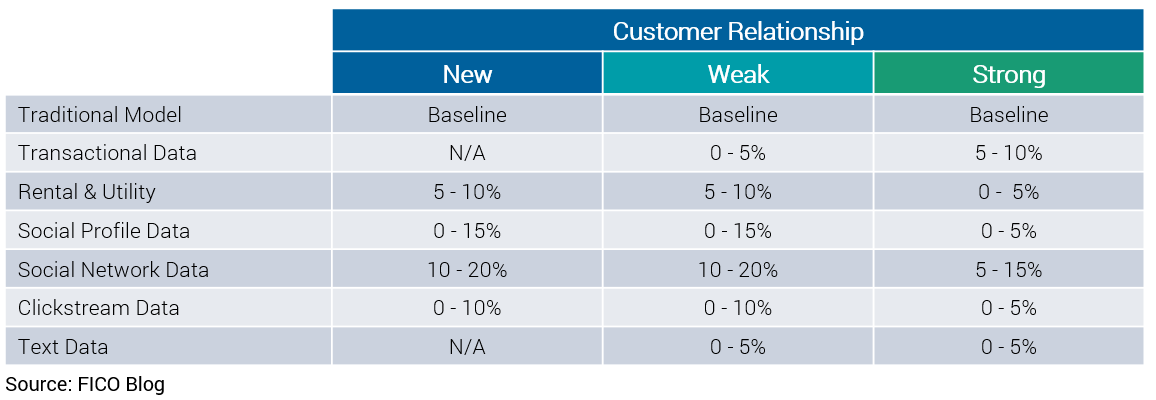
Please note that the Traditional Models used as the baseline were application models, not credit bureau score models (such as the FICO® Score).
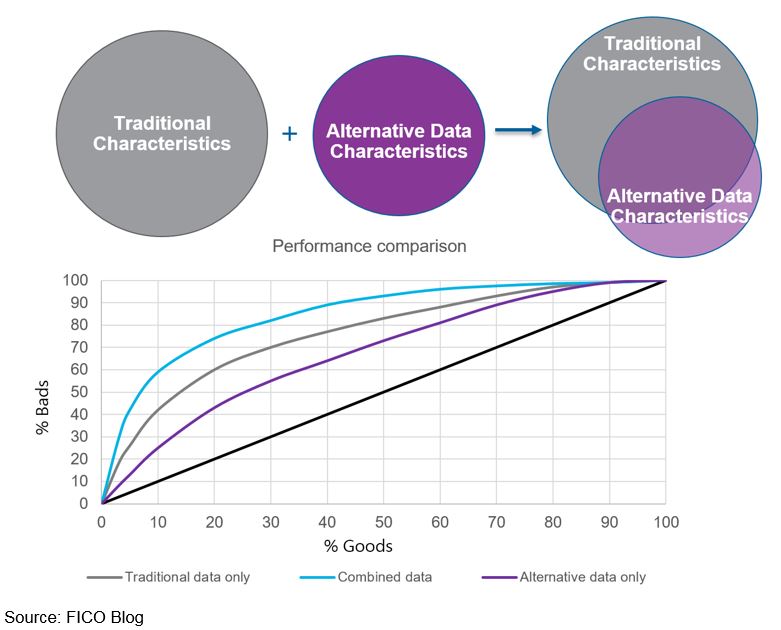
The chart below shows the result of one project FICO did for a personal lending origination portfolio. The traditional credit characteristics captured more value than the alternative data characteristics (with the alternative data capturing about 60% of the predictive power), and there was a high degree of overlap between the two. However, by combining the traditional and alternative data characteristics (and understanding the overlap so as not to over-weigh certain variables’ contribution), we were able to produce a more powerful credit risk model.
Machine Learning and Explainability in Credit Risk Models
It’s impossible to talk about alternative data without talking about different analytic technologies and machine learning, such as neural networks, random forests and stochastic gradient boosting. With large, unstructured data sets, the smart use of these technologies can drive automated discovery of predictive patterns, yield faster insights (particularly on those alternative data sources on which there is little existing expertise) and make the model development process more manageable.
In credit risk modeling, it is also crucial to balance the use of AI/machine learning with deep domain expertise and common sense to ensure model robustness, as well as openness and fairness to consumers.
At FICO, our mission is to innovate new tools that enable lenders to safely expand consumer access to credit and fuel economic growth. With appropriate guardrails, AI can help achieve more equitable outcomes for the next generation. Backed by our 60+ years of experience in credit scoring and deep expertise in developing AI-driven solutions across sectors, FICO is leading the way by expanding the use of alternative data and adhering to the Responsible AI development standard, deploying AI/ML techniques that are: 1) robust, 2) explainable, 3) ethical, and 4) efficient.
For more information on these techniques, see the blog post by FICO Chief Analytics Officer Scott Zoldi on How to Build Credit Risk Models Using AI and Machine Learning.
How FICO Can Help You Use Alternative Data in Credit Risk Analytics
- Explore FICO's solutions for predictive analytics and Responsible AI.
- Discover the analytics capabilities of FICO Platform.
- Read FICO Fact: How Alternative Data Enhances the Accuracy of Consumer Credit Profiles.
- Learn about FICO® Score XD, UltraFICO® Score, and the FICO Financial Inclusion Initiative.
- Explore FICO's solutions for predictive analytics and Responsible AI
- Watch our FICO World video on using alternative data options for expanding credit access
- Read our case study to learn how a Latin American fintech is bringing fair and transparent lending services to an underbanked population
This is an update of a post first published in August 2017.

Popular Posts

Has the Reporting of Rental Data to the Credit Reporting Agencies (CRAs) Increased?
FICO Score 10T includes rental data, but consumers can only experience the benefit of this to the extent that their rental data is reported to the CRAs
Read more
Average U.S. FICO® Score at 716, Indicating Improvement in Consumer Credit Behaviors Despite Pandemic
The FICO Score is a broad-based, independent standard measure of credit risk
Read more
FICO Statement on FHFA and FHA Updates to Credit Score Modernization
FICO supports FHFA’s announcement that the long-anticipated historical data for FICO® Score 10T will be released to the mortgage market.
Read moreTake the next step
Connect with FICO for answers to all your product and solution questions. Interested in becoming a business partner? Contact us to learn more. We look forward to hearing from you.