GPU Acceleration of the Hybrid Gradient Algorithm in FICO Xpress
FICO® Xpress 9.8 comes with a GPU accelerated implementation of the hybrid gradient algorithm, yielding speedups of up to 50x

FICO® Xpress 9.8 (available now) comes with a surprise novelty: a GPU accelerated implementation of the hybrid gradient algorithm, yielding speedups of up to 50x on NVIDIA GPUs. It is available on both Linux (x64 and AArch64) and Windows, supporting GPUs from laptop units such as the MX450 all the way to a top-end H100 (and beyond), and anything in-between.
How did we achieve that? Read on to find out more.
Why Use the Hybrid Gradient Algorithm?
The hybrid gradient algorithm has been available since FICO Xpress 9.4, released in the Spring of 2024. It is a first-order algorithm for linear optimization, capable of reaching modest solution accuracy even for extremely large problems due to its lower memory overhead. The number of hybrid gradient iterations required to complete the method is typically large, but each iteration is very fast. The algorithm can be described in terms of elementary matrix and vector operations. It does not use a factorization step, which is often the bottleneck when trying to speed up the implementation via parallelization.
The CPU implementation of the PDHG algorithm received stability and performance upgrades since its first release. The algorithm saw a 5x speed up on hard models (>100s).
What to Speed Up?
Conventional wisdom has held that the most expensive part of the hybrid gradient algorithm for linear optimization is the computation of matrix vector products. It is true that this is the single most expensive operation in the algorithm, but hardly the dominating factor. The reason for this is that linear optimization problems are often very sparse: there are only a handful of non-zeros in each column of the problem matrix. This means that the cost of a matrix-vector multiplication is only a small multiple of the cost of computing the norm of a dense vector or the scalar product of two dense vectors: operations which appear in every single iteration of the hybrid gradient algorithm. If we speed up only the matrix-vector multiplications (by whatever means, hypothetically reducing them to not taking any time at all), then this would limit the maximum attainable speedup. The following table summarizes problem characteristics and maximum speedups for a few publicly available benchmark instances, if we were to take such an approach. Maximum speedups here refer to the maximum possible speedup against the current CPU implementation if the SPMV operation alone is parallelized in an ideal manner.
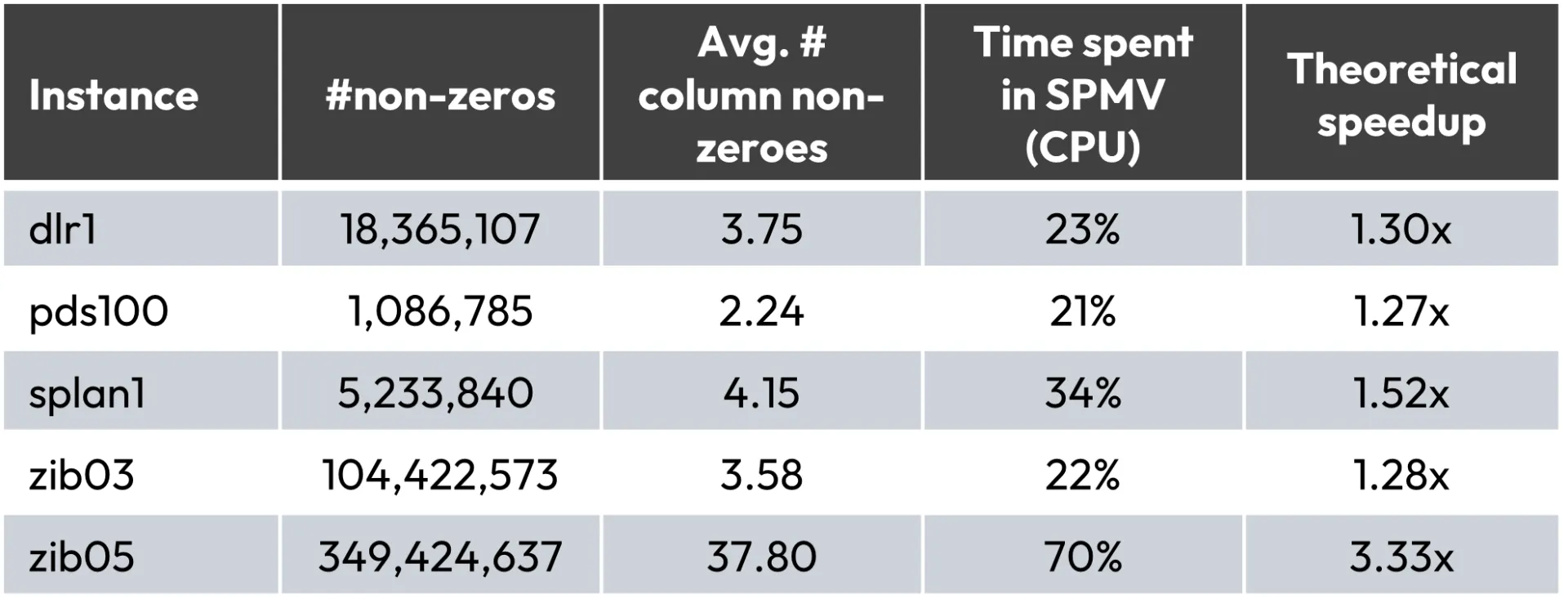
When the average number of non-zeroes per column is low, then the computational cost of a matrix vector product is equivalent to only a few scalar products on dense vectors. It is then not surprising that for these problems only 20-30% of the total time is spent in matrix-vector multiplication.
Moreover, those vector operations do not parallelize well on a CPU, due to their low computational intensity. The overhead of managing and synchronizing the threads can even result in a slowdown. Vectorization with AVX instructions is a boost, but it does not provide nearly the speedup that a parallel implementation on a GPU can.
It is thus clear that only computing matrix-vector products on the GPU is not enough for a highly performant implementation.
GPU Acceleration
Our implementation ports the entire algorithm to the GPU, not just the matrix-vector products, to achieve speedups up to 30x in single precision and 25x in double precision. The GPU and CPU versions of the algorithm are otherwise mathematically identical. A key advantage of GPUs over CPUs is the more efficient parallelization of simple vector operations, thus allowing us to parallelize the entire algorithm. This has contributed to the impressive speedups even on older, less capable GPUs.
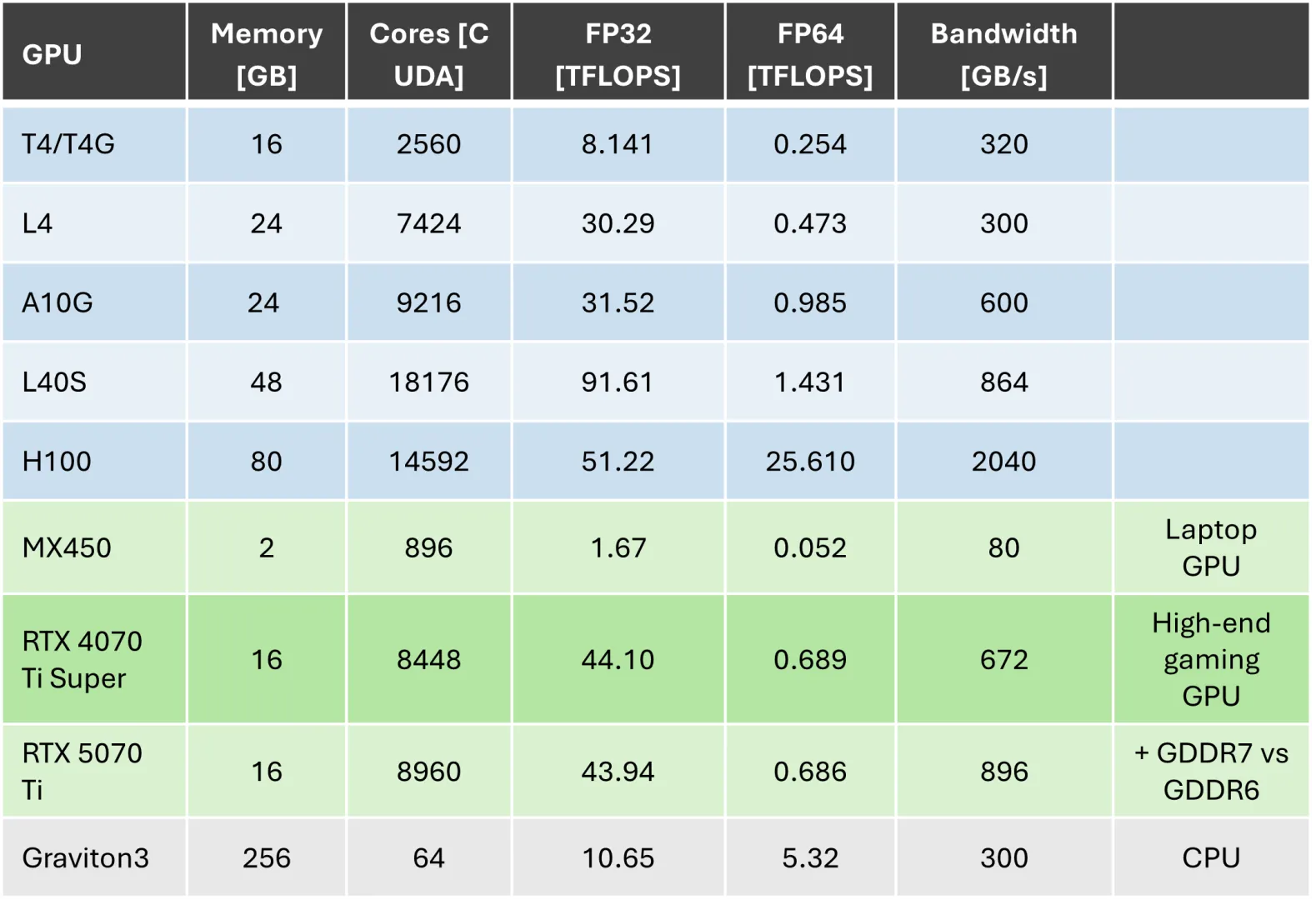
Supported and Tested GPUs
Any NVIDIA GPU with NVIDIA® CUDA® Compute Capability 7.5 or later is supported. Version 580 or later of the NVIDIA drivers is required, along with at least version 13 of the CUDA Runtime. This covers most NVIDIA GPUs released since 2018. We tested a wide range of GPUs, summarized in the following table:
Benchmark Results
The following table lists some representative test problems and their runtimes (in seconds) for the single precision version of the implementation. As a baseline we used a Graviton3, a standard choice on AWS.
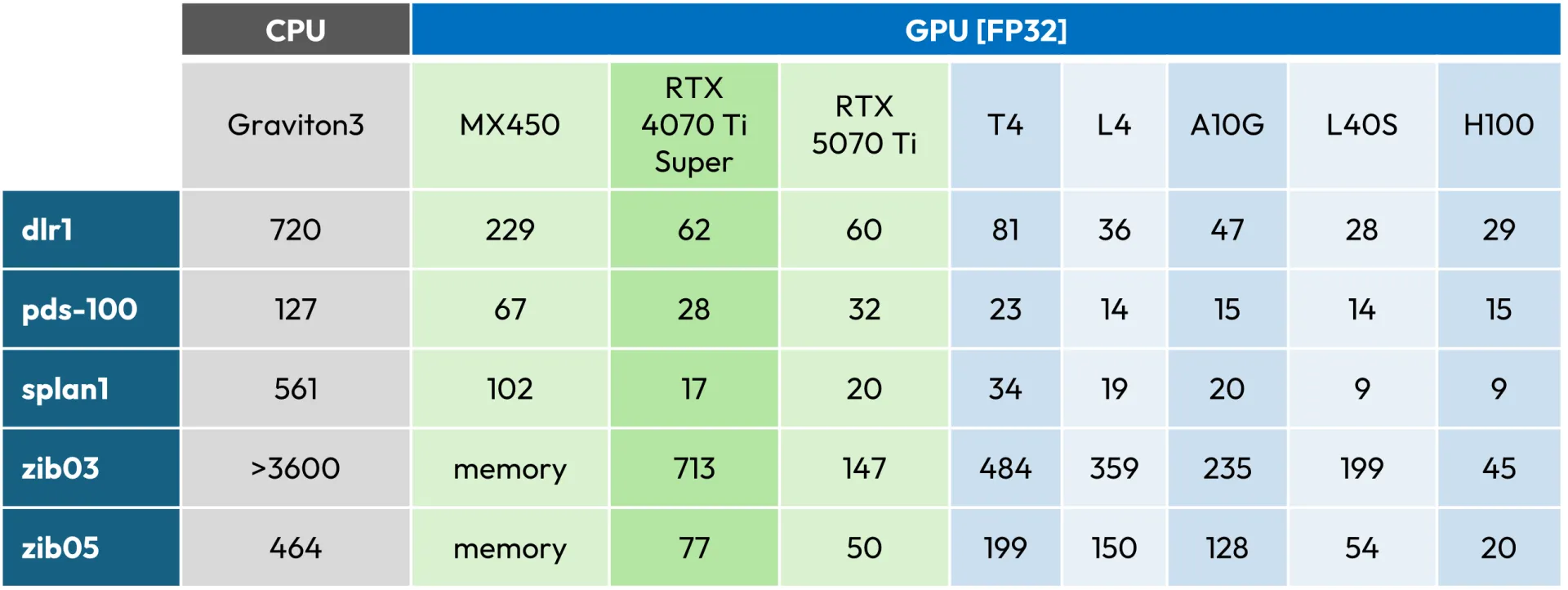
It is important to note that even the simplest and oldest supported laptop GPU (the MX450) yielded some speedups, as long as the problems fit in its 2GB of vRAM. This is because all operations, including scalar products and vector norms, are now parallelized in an efficient way. The speedups for the low-end GPUs in double precision mode were smaller.
Higher-end GPUs were yielding a much better performance, as expected, and could easily solve even the largest problems, thanks to their much larger memory and bandwidth. Crucially, the more capable GPUs gave a significant speedup even for the double precision version of the algorithm.
The implementation was straightforward, with no compatibility issues at all. The NVIDIA developer tools made the process easy.
For a different view of the speedups let us look at 133 public and client instances, which all solved in under an hour in single precision on both a Graviton3 CPU and an NVIDIA L40S GPU. The following scatterplot shows the speedup (GPU vs CPU) versus the number of non-zeros in the presolved problem.
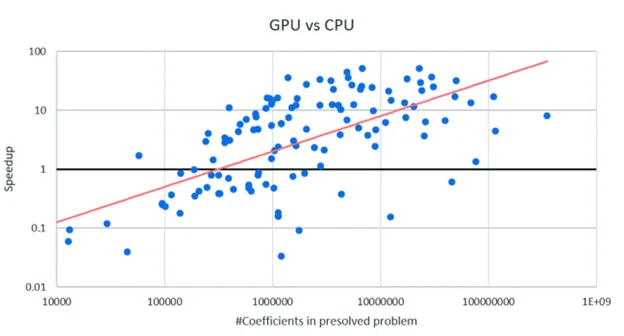
Problems with less than a 100,000 non-zeros hardly benefit from GPU acceleration, they are simply too small. On the other hand, problems with over 10 million non-zeros are almost always (often very significantly) faster on the GPU than on a CPU. This is important when trying to decide whether to use GPU acceleration for a particular problem.
Determinism
Our implementation uses building blocks from cuBLAS and other custom CUDA kernels. Special care was taken to make sure that the implementation is deterministic if run on the same GPU. This is crucial for the reproducibility of the results and the reliability of the implementation and is a standard requirement in the optimization industry.
Availability
GPU acceleration for the hybrid gradient algorithm is available as a beta feature in FICO Xpress 9.8, released in October 2025. A license for Xpress 9.8 is required. The algorithm can also be used in the concurrent linear optimization solver or for solving the root node of a MIP. All that needs to be done is to set the new control BARHGGPU to 1, in addition to setting BARALG to 4. By default, the single-precision floating mode is used on the GPU and the double-precision mode on the CPU. This can be changed with the control BARHGPRECISION. On the GPU the single-precision mode is roughly twice as fast and uses 30% less memory than the double-prevision mode, while yielding solutions of similar accuracy.
Supported platforms and operating systems are Linux on both x64 and aarch64 (such as RHEL 9, Ubuntu 22.04 or AL2023), and Windows (11 or Server 2022).
If you are interested in submitting instances or speaking to us, please write to XpressPerformance@fico.com. If you are interested in obtaining a license of Xpress, please contact us here.
Learn More About Xpress Optimization
- Read GPU-Powered Optimization: FICO's Experience with NVIDIA cuOpt
- Explore the Optimization: FICO® Community Blog
- Discover FICO Xpress Optimization
- Download our case study to learn how PepsiCo leveraged Xpress to execute 400-500 large-scale optimization models daily and reduced daily production solve times by 30% through solver tuning
- Learn more about the benefits of switching to FICO Xpress Optimization and the unique features of each Xpress product
- Request a free 60-day trial license to test out the Xpress capabilities for yourself
- Read the Xpress and DoorDash case study to learn how DoorDash has made complex deliveries up to 100x faster thanks to Xpress.

Popular Posts

Has the Reporting of Rental Data to the Credit Reporting Agencies (CRAs) Increased?
FICO Score 10T includes rental data, but consumers can only experience the benefit of this to the extent that their rental data is reported to the CRAs
Read more
Average U.S. FICO® Score at 716, Indicating Improvement in Consumer Credit Behaviors Despite Pandemic
The FICO Score is a broad-based, independent standard measure of credit risk
Read more
FICO Statement on FHFA and FHA Updates to Credit Score Modernization
FICO supports FHFA’s announcement that the long-anticipated historical data for FICO® Score 10T will be released to the mortgage market.
Read moreTake the next step
Connect with FICO for answers to all your product and solution questions. Interested in becoming a business partner? Contact us to learn more. We look forward to hearing from you.