Application Fraud: The Role of AI and Machine Learning
I spoke with one of FICO’s principal scientists, Derek Dempsey, who shared how AI and machine learning are solving problems in application fraud.


In a recent blog post we explored the underlying concepts behind machine learning and its tremendous benefits in fighting application fraud. Since then, I had the opportunity to speak with one of FICO’s principal scientists, Derek Dempsey, who shared how AI and machine learning are solving problems in application fraud.

Derek has worked in machine learning and advanced analytics for 20+ years, and he is a specialist in the development and application of predictive analytics for application fraud detection. As a man of many talents, when he is not busy fighting crime through intelligent computing, Derek dazzles the London stage as an actor.
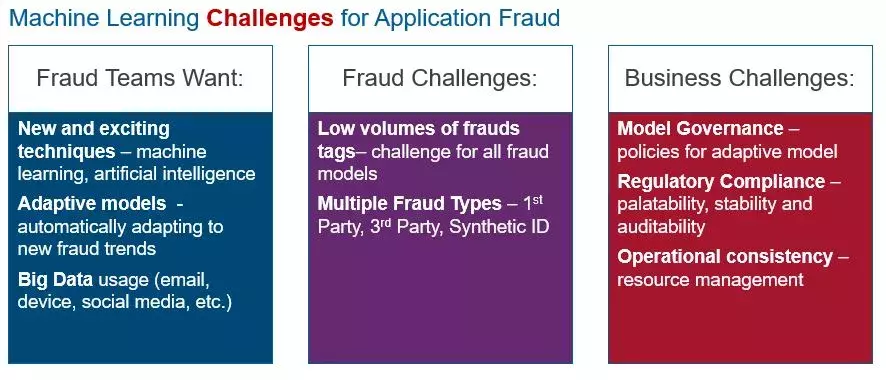
What do you see as the biggest challenges for machine learning to fight application fraud
I think the biggest challenge will be governance and regulation rather than analytical challenges. Building machine learning models will require a deep understanding of how financial institutions work, how fraud is detected, and how fraud is controlled and managed — it’s not just about pointing algorithms at the data.
Broadly speaking, here’s how I see the big challenges in the application of machine learning to fight application fraud:
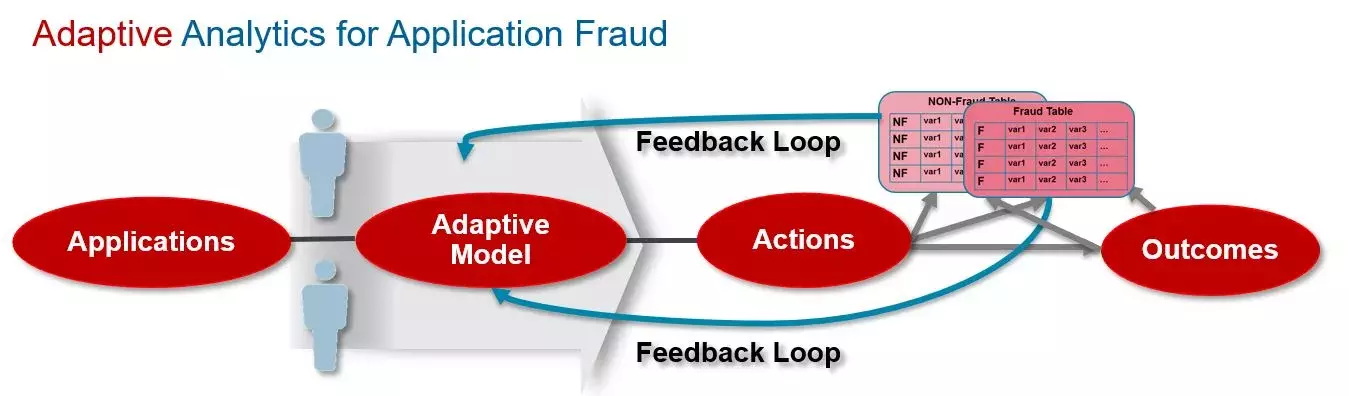
Can you explain what adaptive analytics are, and do you think self-learning models have a place in application fraud?
There are several flavors of adaptive analytics. For example, there are adaptive elements such as real-time adaptive profiles that maintain recursively updated feature detectors applied to individuals or to groups of entities. We also use self-calibrating analytics where the models derive data-driven groupings and distributions that are constantly updated and re-calculated.
Another type of adaptive analytics uses confirmed fraud and non-fraud dispositions from the analysts working cases to adapt model weights so that when new fraud and non-fraud patterns are discovered this information is fed back to improve the model performance. This methodology is very successfully leveraged today in FICO's Falcon Fraud Manager Platform to detect enterprise payments fraud, and is currently under development for application fraud within FICO Application Fraud Manager. We expect this to have a major impact on improving application fraud detection.
Feature generation is something we discussed in our most recent blog as an important part of generating a predictive model. Can you tell us more about the feature generation techniques that provide the most uplift for predictability?
Feature generation is the key to unlocking the value in data. In time series data, we want to look at velocities of activity, for example, time-clustered transactions that are indicative of fraud. In application fraud, two main areas of focus are the generation of features that highlight the risk associated with the applicant and application and network analytics that identifies relationships between applications.
Much of the data available at application is categorical, such as employment status, occupation, and residential status. Handling these categorical risk variables through risk tables and generation of indicators is critical for effective analytics. However, we need to enhance these features through the development of velocity variables and network variables to extract maximum information from the data and detect different types of fraud attack.
In application fraud, another area where we see significant uplift is through fuzzy matching, for example, against previous applications. We see that fraudsters often make several attempts to commit application fraud using slightly varying details to gain access to credit products, e.g. changing address, name, occupation or salary details, etc. The ability to fuzzy match against previous applications – and other data sources - and identify possible matches is important. This information can also be included within the models as additional features. Brute force and botnet attacks can also be quickly identified using this method.
This signal and feature generation process can be further bolstered through social network analytics (SNA) to uncover links between fraudsters and their clever tactics to uncover fraud faster. FICO SNA provides this powerful capability as discussed in a recent FICO webinar: http://www.fico.com/en/latest-thinking/on-demand-webinar/layered-defenses-in-the-fight-against-application-fraud
When operationalizing machine learning models for application fraud in an originations environment, what considerations should be undertaken?
One critical factor is to ensure that the operational data environment is aligned to the model data specification. Another key factor is to ensure that the end-users, the business team, understand the detection rates and false positive rates associated with the model. This must be explicit in the model report so that the operational teams can define appropriate thresholds to manage the fraud cases and prioritize queues.
The 'interpretability' of the model is also of critical importance, as results must be explainable not only to the fraud analyst but also as part of the broader regulatory regime. The fraud analyst needs to understand why the model has scored this application high to understand quickly the possible fraud type and the additional checks required. FICO provides model reason codes that indicate the main features contributing to the model score. More broadly, while fraud checks are excluded from much regulation, the model governance teams need to be able to confirm that bias is not being introduced into the originations process. See Scott Zoldi's post on explainable AI.
Lastly, the production environment and business requirements around score generation need to be accounted for in the model design. All environments are dynamic: OS upgrades happen, system upgrades, security patches and so on. Models become part of this ecosystem and, as such, need to be robust and maintainable. The recent move to cloud-based solutions removes most of these dependencies, however, and this move to cloud has been a core element of FICO strategy in recent years.
What kind of uplift can a financial institution anticipate from using an analytic approach for application fraud, over and above a rules-based approach?
We typically estimate uplift in the order of 30% - 40% in terms of fraud detection but this is dependent on many factors and can be much higher.
As with all types of fraud detection, layered controls are critical. A rule makes sense when you have a well-defined knock-out (KO) criterion — for example, this ID is on our negative list as a fraudster so exclude them. This doesn't need a sophisticated model - it's a simple KO rule. Where analytic gains are most significant is by combining “soft” rules and indicators into a sophisticated algorithmic calculation that will utilize multiple features and result in much greater accuracy.
As I mentioned earlier, feature generation creates a much richer data representation that allows the algorithms to outperform rules significantly.
I know FICO scientists are working currently on a consortium model for application fraud — why should clients be excited?
A consortium model uses data from multiple organizations, and this rich data set can provide a huge gain in power. We build consortium models for payments fraud using the Falcon Intelligence Network, and you can read more about this approach in this post from FICO’s TJ Horan. . Using this kind of consortium allows a standardization of data requirements, tools and techniques and this in turn facilitates research into new machine learning techniques applied to produce increasingly powerful models. The consortium data is used for model development and innovation, but is not shared between contributors — for example, negative file lists are not shared as part of this approach.
We expect to see big benefits from a consortium solution in application fraud by utilizing the feature generation methods and advanced machine learning techniques such as multi-layer self-calibrating models, collaborative profiles and Adaptive Analytics. Adaptive Analytics utilizes both the fraud and non-fraud dispositions from the fraud analysts to re-optimize model weights and enable a rapid response to new fraud trends as well as reducing false positives.
A fraud consortium like the one we’re building is much more than just sharing data. It is about transforming fraud prevention with data-driven methodologies and continuous model improvement to find fraud an individual lender has not seen before.
Thanks, Derek, for your time, it was a pleasure meeting and learning from you!
Want to learn more? Check out our previous posts on application fraud:
- Trends in Application Fraud – From Identity Theft to First-Party Fraud
- Best Practices in Establishing Your Fraud Risk Appetite
- ELI5: What does the Dark Web have to do with Application Fraud
- Data, data, data: Application Fraud and the elephant in the room
- Preventing Application Fraud with Machine Learning and AI
- 4 Success Factors for Machine Learning in Fraud Detection
Popular Posts

Has the Reporting of Rental Data to the Credit Reporting Agencies (CRAs) Increased?
FICO Score 10T includes rental data, but consumers can only experience the benefit of this to the extent that their rental data is reported to the CRAs
Read more
Average U.S. FICO® Score at 716, Indicating Improvement in Consumer Credit Behaviors Despite Pandemic
The FICO Score is a broad-based, independent standard measure of credit risk
Read more
FICO Statement on FHFA and FHA Updates to Credit Score Modernization
FICO supports FHFA’s announcement that the long-anticipated historical data for FICO® Score 10T will be released to the mortgage market.
Read moreTake the next step
Connect with FICO for answers to all your product and solution questions. Interested in becoming a business partner? Contact us to learn more. We look forward to hearing from you.