What Are Fraud Analytics and How Do They Improve Fraud Detection?
Understand what fraud analytics entail and how they leverage AI, machine learning, business intelligence and data science to improve fraud detection


Understanding Fraud Analytics and the Role of AI and Machine Learning in Fraud Detection
The recent fascination with artificial intelligence and machine learning has made some of us (naturally intelligent) humans confused about the role that these technologies play in the broader field of fraud analytics. In this blog post, I explain their usage and particularly how they will operate in the open banking revolution.
What Are Fraud Analytics?
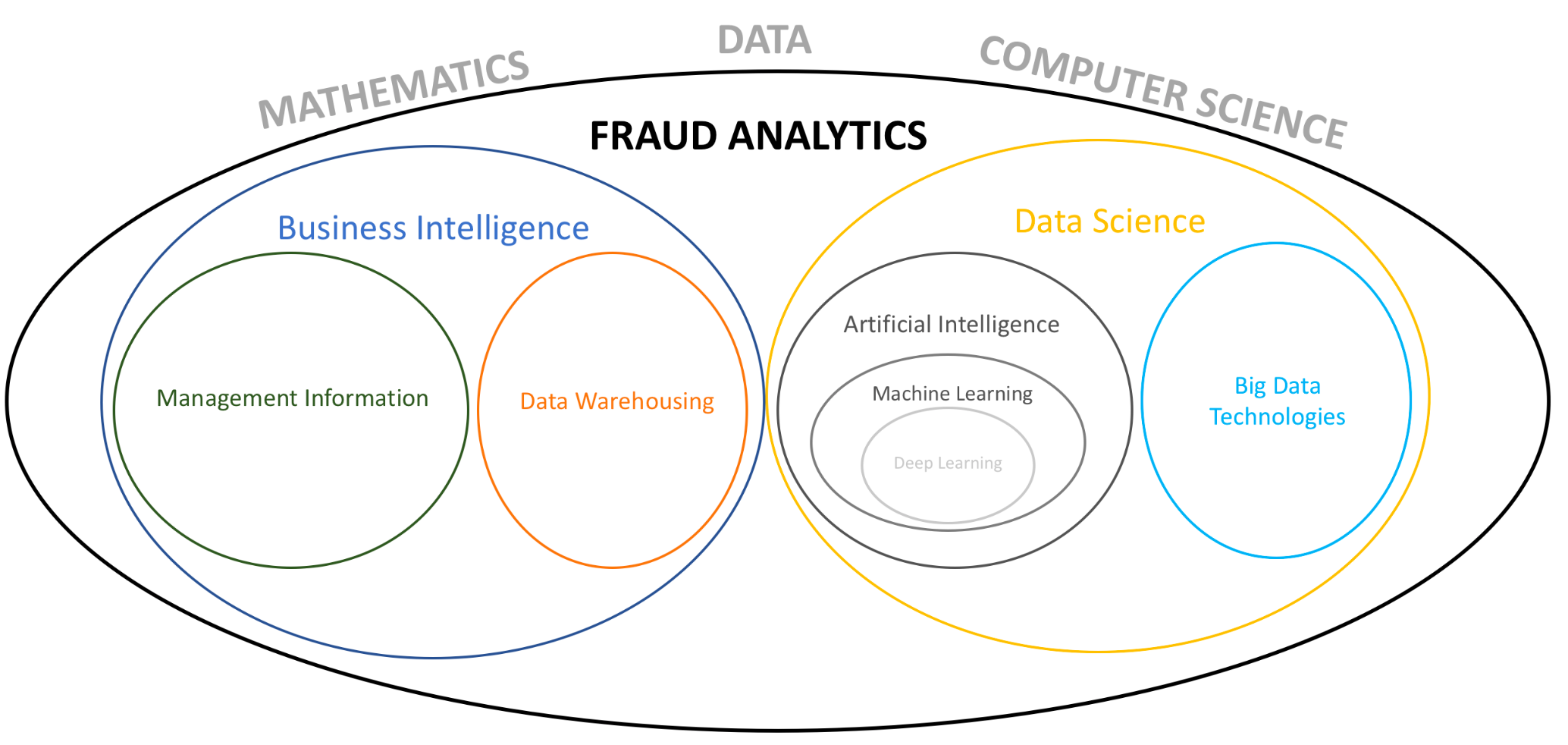
Generally speaking, fraud analytics can be defined as a multidisciplinary field that combines numerous quantitative sciences in order to better understand fraud - for example, through business intelligence (BI), data mining, machine learning and AI - and develop effective fraud detection solutions through data science. Fraud analytics is an umbrella term covering a lot of technologies — let’s look at the two big categories for fraud prevention: business intelligence and data science.
Source: FICO Blog
The Benefits of Fraud Analytics
Fraud analytics offers substantial benefits, including:
- Early fraud detection: fraud analytics helps identify emerging fraud patterns in real-time and proactively stop threats before fraud occurs.
- Fraud patterns identification: fraud analytics reviews and audits large amounts of data and identifies behavioral patterns to improve fraud detection.
- Improved customer experience and trust: fraud analytics reduces the impact of criminal activity on customers, giving them greater trust in the institution.
- Improved brand reputation: fraud can be very damaging to a brand's reputation. Being able to prevent major fraud incidents and showing a commitment to protecting customers sends a very positive message.
- Mitigated financial loss: catching fraud before it occurs means minimizing fraud losses, but also the costs associated with fraudulent transactions, chargebacks, investigations, and potential customer attrition.
Fraud Analytics and Business Intelligence
In the fraud management space, BI can be thought of as a descriptive performance reporter. It summarizes available data to provide business dashboards and insights to business leaders and fraud managers so they can make more informed decisions. This can involve, for example, analyzing the performance of fraud strategy rules.
For BI to do its job, you need a robust data warehousing architecture so that data can be easily accessed for management information (MI) purposes. MI relates to creating executive dashboards, data visualisation, data storytelling and any other reporting methods.
Fraud Analytics and Data Science
Data science relates to a set of more sophisticated technologies for performing predictive and prescriptive analytics. Predictive analytics is focused on making predictions about the future of unknown events (or, in the case of fraud, current events outcomes). Prescriptive analytics relates to choosing the optimal course of action based on the outcome of those predictions.
Increases (volume) in available data of different types (variety) and data often arriving in streams (velocity) have led to a development of Big Data tools such as Hadoop and Kafka. Critically, traditional data storage and processing systems are not efficient enough to deal with the aforementioned three Vs of Big Data. Once in a Big Data store, analysts can work with the data and develop an understanding of the features that are predictive when detecting fraud.
The Role of Artificial Intelligence and Machine Learning in Fraud Analytics
Artificial Intelligence, Machine Learning, and Deep Learning
Arguably the most exciting technologies in fraud analytics today are artificial intelligence (AI), machine learning and deep learning.
- AI relates to the computer implementation of human thought processes in a computerized and efficient fashion.
- Machine learning is a subset of AI that relates to the science of algorithms. Machine learning is a set of numerous algorithmic techniques can be used to extract complex relationships in data which a human could not find.
- Deep learning is a class of machine learning algorithms focused specifically on building “deep” (multi-layered) neural networks, a form of AI widely used in fraud detection.
The Three Types of Machine Learning
There are three major types of machine learning:
- Supervised learning is focused on making inferences from labelled historical data where labelled data can represent, for example, transactions that were found to be fraudulent or genuine in the past.
- Unsupervised learning is used to make inferences from datasets consisting of instances without labelled responses.
- Semi-supervised learning is a combination of the two other types. It can make use of both labelled and unlabelled data and allows for human and machine collaboration.
Often, organized crime schemes are very sophisticated and quick to evolve. Therefore, AI systems to be used for fraud detection must include both supervised and unsupervised models to build comprehensive and next-generation defense strategies. AI systems combining unsupervised and supervised machine learning techniques can detect previously unseen forms of suspicious behavior while quickly recognizing the more subtle patterns of fraud that have been previously observed across billions of accounts. A good example of this occurs in our FICO Falcon Fraud Manager.
Supervised learning may be difficult to apply to open banking because the evolution of open banking in terms of adoption is still unclear and the access to historical tagged fraud data is very limited Therefore, unsupervised machine learning provides a valuable alternative, for those that do not have large data stores of fraud and non-fraud transaction data. They can construct data sets that are expected to simulate the upcoming open banking environment or benefit from previous open banking launches.
Why Use Machine Learning for Fraud Detection?
As noted above, machine learning for fraud detection refers to a set of analytic techniques and algorithms that “learn” to differentiate between fraudulent and genuine transaction patterns to make automated decisions without being guided by a human analyst. For our purposes, think of machine learning models as building blocks of AI systems such as FICO Falcon Fraud Manager. Such building blocks perform thousands of computations in milliseconds to continuously adapt to new incoming data, allowing them to clearly distinguish fraudulent and genuine transaction patterns in real time. A robust AI system for fraud detection must include well-architected and domain-specific machine learning models supported by a toolkit of data science techniques for raw data transformations, feature selection and model training stages.
How Machine Learning and Behavioral Analytics Support Fraud Detection
Behavioral analytics is an essential tool for fraud detection, it uses machine learning to understand and anticipate behaviors at a granular level across each aspect of a transaction. The information is tracked in behavioral profiles that represent the behaviors of each individual, merchant, account and device, compactly summarizing their transactional histories using analytic functions and machine learning algorithms. These profiles are updated with each transaction, in real time, in order to compute analytic characteristics and features that provide informed predictions of future behavior.
Behavioral profiles contain details of monetary and non-monetary transactions. Non-monetary transactions include a change of address, a request for a duplicate card or a recent password reset. Monetary transaction details support the development of patterns that may represent an individual’s typical spend velocity, the hours and days when someone tends to transact, and the time period between geographically disperse payment locations, to name a few examples. Profiles are very powerful as they supply an up- to-date view of activity used to avoid transaction abandonment caused by frustrating false positives.
A robust enterprise AI fraud detection system combines a range of machine learning models and behavioral profiles, which contain the details necessary to understand evolving transaction patterns in real time. A good example of this occurs in our FICO Falcon Fraud Manager.
Given the sophistication and speed of organized fraud rings, behavioral profiles must be updated with each transaction. This is a key component of helping financial institutions anticipate individual behaviors and execute fraud detection strategies, at scale, which distinguish both legitimate and illicit behavior changes.
5 Behavioral Profiles That Are Critical for Effective Fraud Detection
Transaction profiles
Behavioral profiles use machine learning to track each entity’s (consumer, merchant, device) financial and non-financial activity. Transaction profiles enable FICO Falcon Fraud Manager to detect subtle, yet anomalous changes in behavior and elevate the score on the transaction. Each profile is a continuous learning cognitive “mini-model” that uses machine learning to interpret behavior in real time with each transaction, across all channels.
Collaborative profiles
These improve fraud detection by identifying behaviors that differ from typical behaviors within individuals’ peer groups. Collaborative profiling is a powerful technique that can be used to detect whether an individual behaves anomalously in relation to a peer group or groups which they belong to.
Collaborative profiling recursively estimates predictive features, meaning that the peer group allocation for the current individual is calculated given the previously observed data and the current information. Collaborative profiling also has self-calibrating abilities, where peer group allocations adapt to population changes and drifts. Collaborative profiling uses unsupervised machine learning, and any significant deviations from the expected behavior can be indicative of fraudulent and suspicious activity worth further investigation.
Behavior sorted lists
Along with the transaction profiles, FICO Falcon Fraud Manager also uses some other specialized machine learning algorithms that can help to increase fraud detection rates and reduce the number of false positives. Individuals form habits and by analyzing their transactional history we can learn their patterns of behavior. Generally, individuals use the same gas stations, go to the same merchants and transfer money to recurring destinations. The technology underlying behavior sorted lists enables FICO Falcon Fraud Manager to create and maintain a real-time ranking of features associated with each individual’s most frequent behaviors. Frequent activities have higher ranks and are less likely to be fraudulent.
Merchant profiles
Merchant profiles are a version of transaction profiles using machine learning to create a more comprehensive view of fraud threat at a merchant level.
Multi-layered self-calibrating models
These models detect behavioral outliers in real time even with limited or no historical tagged fraud data to train the model, and automatically adjust to accommodate new behavioral patterns. Advanced instances use deep learning to further improve fraud and anomaly detection. Multi-layered self-calibrating models use machine learning and statistical techniques to dynamically scale variables stored in transaction profiles, estimate their value distributions and determine the outliers in key fraud feature detectors. The distribution of key fraud feature detectors is expected to change over time due to the dynamic nature of the open banking environment — what is an outlier today may be normal tomorrow. Therefore, for an AI fraud detection system to be robust, it must be able to determine the outliers “on the fly” in a production environment by analyzing the changes in the distributions of features stored in transaction profiles.
The Importance of Adaptive Analytics and Self-Learning AI In Fraud Analytics
For continual performance improvement, fraud detection professionals should consider adaptive technologies designed to sharpen responses, particularly on marginal decisions. These are the transactions that are very close to the investigative triggers, either just above or just below the cutoff. It is on these margins where accuracy is most critical as there is a fine line between a false positive event — a legitimate transaction which has scored too high, and a false negative event — a fraudulent transaction which has scored too low. Adaptive analytics sharpen this distinction with up-to-date knowledge of the threat vectors an institution is facing.
Adaptive technologies improve sensitivity to shifting fraud patterns by automatically adapting to recent confirmed case disposition, resulting in a more precise separation between frauds and non-frauds. When an analyst investigates a transaction, the outcome — whether the transaction is confirmed as legitimate or fraudulent — is fed back into the system to accurately reflect the fraud environment that analysts are facing, including new tactics and subtle fraud patterns that have been dormant for some time. This adaptive modeling technique automatically modifies the weights of predictive features within the underlying fraud models. It is a powerful tool that improves fraud detection performance on the margins and stops new types of fraud attacks.
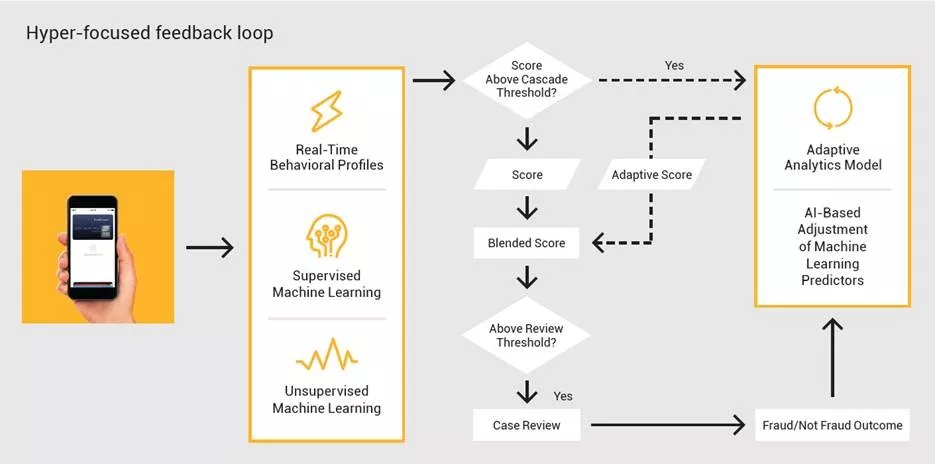
FICO uses adaptive analytics to balance the benefits of a model developed with data from thousands of institutions with the ability to quickly learn unique fraud patterns from an individual institution and boost fraud performance and responsiveness.
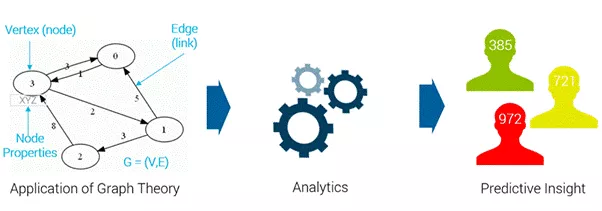
Using Social Network Analysis to Identify Fraudulent Activities
Another form of fraud analytics used in fraud detection is social network analysis. This is an analytic approach of correlating people, entities and relationships to determine how tightly an individual or business is related to others who have known fraud or money laundering issues. These relationships can be from shared phone numbers, physical addresses, bank accounts, credit cards, or any other connection that is available through data capture. The results of the social network analysis can show the risk that a specific individual or business presents, based on their relationship with others who have known issues within the network. As can be seen below, using graph theory and analytics, we gain can valuable insights into specific members of the network.
How FICO’s Fraud Analytics Solutions Can Help You with Fraud Prevention
- Explore FICO Falcon Fraud Manager
- Discover our solutions for fraud and financial crime prevention
- Learn more about neural networks and deep learning
- See a roundtable discussion on Advances in Fraud Protection with Teradata, Itaú Unibanco, Datos Insights - FICO World 2024
This is an update of a blog post originally published in 2018.

Popular Posts

Has the Reporting of Rental Data to the Credit Reporting Agencies (CRAs) Increased?
FICO Score 10T includes rental data, but consumers can only experience the benefit of this to the extent that their rental data is reported to the CRAs
Read more
Average U.S. FICO® Score at 716, Indicating Improvement in Consumer Credit Behaviors Despite Pandemic
The FICO Score is a broad-based, independent standard measure of credit risk
Read more
FICO Statement on FHFA and FHA Updates to Credit Score Modernization
FICO supports FHFA’s announcement that the long-anticipated historical data for FICO® Score 10T will be released to the mortgage market.
Read moreTake the next step
Connect with FICO for answers to all your product and solution questions. Interested in becoming a business partner? Contact us to learn more. We look forward to hearing from you.